Pinteresque: het Platform
Inhoudsopgave
1 Samenvatting
Pinteresque voert, als kapperbezoeker, het obligate gesprek met de kapper of kapster. Pinteresque is een gespreksbot of voice-assistant Meer over het doel van dit project in Hoe moeten mens en machine versmelten.
De doelgroep bestaat natuurlijk niet alleen uit kappers (Pinteresque in de praktijk toegepast), maar ook kappersscholen en publiek dat geïnteresseerd is in de confrontatie met een kunstmatige gesprekspartner en niet afgeschrikt wordt door het spelen van de rol van kapper of kapster.
Het model waarmee Pinteresque het gesprek stuurt is vervangbaar. Niet alleen gesprekken met een kapper kunnen worden vormgegeven, ook personeelsselectie (zoals getoond op het Omkeerevent van NSvP op 18 juni 2019) en het invullen van formulieren behoren tot de toepassingsgebieden.
Er is gekozen voor intent-matcher in combinatie met een looking for clues-oplossing.
De dialoog wordt dus gedreven door:
- intents zoals uitgesproken door de echte persoon en gematcht door de intent-matcher.
- clues, known-unknowns over de echte persoon die de reacties van de gespreksbot prioriteert totdat ze opgelost zijn.
De software gaat op zoek naar elk onderdeel van een vooraf vastgestelde verzameling clues, informatie die niet beschikbaar is over de gesprekspartner. Dat gaat dan om naam, leeftijd, knipwens en bereidheid tot een gesprek. Ook al of niet aanwezige competenties kunnen daarmee worden uitgezocht.
Elke intent (een naam en een verzameling teksten met een voor de persoon gelijkwaardige betekenis) kent één of meer gespreksbot-reacties. In het model wordt aangegeven welke clue door die reactie wordt opgelost.
Clues hebben een prioriteit en de software zal alles proberen om die op te lossen, hoogste prioriteit eerst. Bij gelijke prioriteit wordt toeval gebruikt voor het kiezen van de reactie.
Omdat clues soms onvoldoende goed gematcht worden door de NLU, kan
er geholpen worden met optionele grammaticale eisen voor elke
clue. Zo zal t ADJ WW ervoor zorgen dat bij twijfel gekozen wordt
voor een clue met een of meer adjectieven en/of werkwoorden. Dat
sluit lidwoorden dus uit.
Een typische Pinteresque dialoog wordt gedreven door deze clue-prioriteiten en door wat de ander zegt (intent).
Vandaar dat geen dialoog hetzelfde is; zelfs indien de persoon die spreekt zinnen uitspreekt die niet bij een intent passen, dan zal de dialoog weer op het goede spoor komen, omdat het oplossen van de clues vragen oproept die de persoon moeilijk vermijden kan.
De clues, intents en teksten zijn vervat in een zogenaamd model. Een typisch model bevat 100 intents met elk 5 intent-matches en 5 reactie-teksten. Een model is meestal op zoek naar tussen de vijf en dertig clues.
Dit document adresseert de IT rondom Pinteresque, aka het platform. Alle componenten die betrokken zijn bij de applicatie Pinteresque worden in dit document beschreven en uitgeschreven. Dit document bevat dus ook alle programma-code van Pinteresque.
Een van de andere implementaties op basis van Pinteresque is die van de Selection Automat: een personeelsselectiemachine. Omdat het kappersgesprek veel overeenkomsten vertoont met een selectiegesprek, is de manier waarop Pinteresque omgaat met antwoorden en, belangrijker, met informatie die de persoon prijsgeeft, heel geschikt voor het voeren van een sollicitatiegesprek. Met Pinteresque als interviewer wel te verstaan!
In 2020 is Pinteresque ingezet voor weer een ander doel: de Sorry Automat (dat is de werknaam). Collectief Smelt wilde in het kader van Tech Sorry een installatie maken waarbij de deelnemer wordt geinterviewd en een persoonlijk excuus krijgt voorgelezen. Een en ander leek goed op Pinteresque te passen en na wat aanpassingen is een en ander op 9 november opgebouwd en op video vastgelegd. In aanvang zou de installatie op het Spring festival te zien zijn, in de centrale bibliotheek van Utrecht, maar als gevolg van de COVID-19 risico's is de fysieke presentatie aan groepen afgeblazen.
De match van Pinteresque met de automaat van Collectief Smelt (Myrthe en Dorian) leek in eerste instantie erg goed. Een automaat die op zoek gaat naar clues en vervolgens een conclusie trekt. De Selection Automat deed dat al, dus deze automat moet dat ook kunnen. Het verschil is echter dat de Selection Automat clues vindt en vervolgens, niet-transparant, conclusies berekent en een groen of rood etiket afdrukt. De Sorry Automat moet in haar excuses sommige clues reproduceren. Daar waar de vorm waarin de clues gematcht worden in de Selection Automat niet erg belangrijk is, is die voor de Sorry Automat juist wel belangrijk. Enige aanpassingen waren dus noodzakelijk, en dan nog is het allemaal niet perfect. Dat was bij de Selection Automat ook niet zo, maar dat merkte niemand. In de Sorry Automat komt foutief woordgebruik of verkeerd verstane woorden meteen boven drijven.
1.1 Summary
Pinteresque, as a hairdresser visitor, has the obligatory conversation with the hairdresser. Pinteresque is a conversational bot or voice assistant
The target group is of course not only hairdressers (Pinteresque applied in practice), but also hairdressing schools and the public interested in the confrontation with an artificial conversation partner and not deterred by playing the role of hairdresser.
In addition, the conversation is controlled by a model that is replaceable. Not only conversations with a hairdresser can be designed, but also the bot-half of well-known dialogues (such as text from Bert & Ernie, or conversations from The hitch-hickers guide to the Galaxy, but then in Dutch).
Pinteresque uses two concepts for driving the dialogue:
- intents as spoken out by the real person
- clues which are to be solved by the software
The intents are sentences to be recognized by the software, retrieving interesting clues from these sentences. Clues like name, age, hairstyle, occupation, whether the shop was easy to find etc. etc.. Every set of intents (a group with similar meaning), has some slightly different lines in order to recognize the intent and a set of texts associated, used by the software to reply, react or induce other clues. Clues have a priority and the software will try to solve all clues, highest priority first.
A typical Pinteresque dialogue is driven by what these priorities are, but also by what the other person says (which end up as intents). As most intents have more than one text for the software to use, randomness comes in as well. Hence no dialogue is the same; even if the person speaking uses lines which do not fit any intent, the dialogue will go back on track because solving the clues raises questions the person finds hard to avoid.
The clues, intents and texts are contained in a so called model. A typical model contains 40 intents with 5 lines and 5 texts each. Persons involved typically have 20 clues (the persona inside the software has the same clues, but then already filled in).
One of the other implementations based on Pinteresque is that of the Selection Automat: a personnel selection machine. Because the hairdresser's interview has many similarities with a selection interview, the way Pinteresque deals with answers and, more importantly, with information revealing the person, is very much suitable for conducting a job interview. With Pinteresque as an interviewer, that is!
2 Waarschuwing
In dit document wordt het Pinteresque meerdere keren uitgelegd, steeds op een ander abstractieniveau of vanuit een andere blik. Ofschoon gepoogd wordt een breed publiek te adresseren, zullen sommige invalshoeken, noodzakelijk voor een compleet verhaal, saai en/of onbegrepen zijn. Dat is niet erg, zolang dat niet voor alle lezers hetzelfde stuk is.
3 Pinteresque
3.1 Spraakrobots en voice-assistants of gespreksbots
In dit document wordt de term spraakrobot gebruikt als verzamelterm voor de meer gespecialiseerde voice-assistants en gespreksbots.
Een spraakrobot kent verscheidene onderdelen:
- ASR; Automatic Speech Recognition (of Speech to Text)
- NLU; Natural Language Understanding
- intent en slot analyse
- NLP; Natural Language Processing (b.v. grammaticaal, toon, perspectief, woordenlijsten)
- applications, zoals b.v. Pinteresque, die alles orchestreert, maar ook kan rapporteren over elk gevoerd gesprek.
- TTS; Text to Speech
Elke gesproken tekst veroorzaakt gebeurtenissen die chronologisch door bovenstaand lijstje heen gaan. Soms vallen ASR en NLU samen voor een betere kwaliteit, soms is NLU apart, maar kent ASR ook een eigen NLU onderdeel. Bij een voice-assistant staat ASR en daardoor ook de rest, uit, totdat er een wake word wordt gebruikt. Naast een signaal voor het begin van tekst is er ook een einde nodig; meestal is dat een pauze van 400ms of meer. Bovenstaande onderdelen staan doorlopend met elkaar in verbinding, zei het dat het om éénrichtingsverkeer gaat. In hedendaagse Internet-termen zou je het een streaming-model kunnen noemen. De pauze van 400ms is belangrijk vanwege het niet-streaming karakter van ons gebruik van de gespreksbot. TTS zal namelijk pas iets gaan doen als ASR een tijdje stil is. Mensen houden nu éénmaal niet van doorelkaar praten1.
Kaldi, een ASR-omgeving, gebruikt haar taal-model om te toetsen of de woorden die van de gesproken tekst gemaakt zijn, kloppen met wat normaal is in die taal. Kaldi kan op die manier eerdere interpretaties terugnemen en vervangen door betere op basis van wat er verderop in het stuk spraak is gehoord. Kaldi heeft NLU (en NLP) dus in het ASR-deel geïntegreerd.
Intent en slot analyse en NLU vallen bij een voice-assistant vaak samen. Voor intent- en slotanalyse zal vooraf training voor NLU plaatsvinden. De NLU-engine ontvangt tekst en zal die geannoteerd uitsturen; intent-naam en slot-namen en waardes (met confidence-levels) worden aan de applicatie geleverd. De applicatie heeft vervolgens de beschikking over een beperkte, tevoren te voorspellen, verzameling van bedoelingen die eenvoudig gematcht kunnen worden met de intent-naam.
Intents zijn vooraf ingestelde patronen waarmee de NLU wordt getraind. Zo zal een applicatie die kan kennismaken onder intent-naam naam uitwisselen de volgende intents kennen:
naam uitwisselen:
- Hoi, ik heet naam.
- Mijn naam is naam.
In bovenstaand voorbeeld is het gebruik van naam een zogenaamd, althans volgens Snips, slot (in Rasa-speak heet dat een Entity). Dat is een in de applicatie te gebruiken waarde die uit de tekst gehaald wordt. De meeste intent-analysers kunnen, mits getraind, dergelijke slots en de waardes ervan, overdragen aan de gebruiker ervan. Pinteresque gebruikt de term clue voor intent-slots.
Met als input “Hoi, ik heet Piet” zal de genoemde kennismakings-assistant een teken krijgen dat er een intent gematcht is, nl. naam uitwisselen en ook nog dat het slot naam de waarde piet heeft.
Omdat de intent-engine enig begrip heeft van de gebruikte taal is het van belang om het gebruik van dergelijke slots van veel voorbeelden te voorzien. Dan kan bij de vertaling naar patronen (de reguliere expressies) rekening gehouden worden met het soort woord en de context2.
De intent-definitie van drie alinea's terug, ziet er dan zo uit (de Snips en Rasa notatie wordt gebruikt, die ook voor Pinteresque wordt ingezet):
## naam uitwisselen:
- Hoi, ik heet [Piet](naam)
- Mijn naam is [Karel](naam)
- Mijn naam is [Antoinette](naam)
Het is vervolgens aan de applicatie om te bepalen wat er met de intent gebeurt. Pinteresque zal als reactie op een dergelijke intent de eigen naam proberen duidelijk te maken of een vervolgvraag stellen. Daarvoor bestaan geen veelgebruikte formaten, maar voor de hand liggend is om iets te gebruiken dat vergelijkbaar is met het intent-formaat.
Zo kan de reactie op een naam uitwisselen intent zo geformuleerd worden voor de uitgaande richting, de kant van TTS uit:
## naam uitwisselen:
- Hoi, ik heet Pinty
- Mijn naam is Pinty
- Pinty is mijn naam
De gespreksbot zal dus bij het binnenkrijgen van de intent naam uitwisselen één van de uitroepen kiezen die in de uitgaande teksten genoemd wordt onder het label: naam uitwisselen. Pinteresque doet het op deze manier en voegt daar nog aan toe dat de bot eigen slots (aka clues) met waardes kent en die zal invullen:
## naam uitwisselen:
- Hoi, ik heet (naam)
- Mijn naam is (naam)
- (naam) is mijn naam
Met bovenstaande tekst zal Pinteresque in staat zijn om de eigen voor-geconfigureerde naam te gebruiken in de tekst die uitgesproken wordt. Dit opent de weg naar meerdere persoonlijkheden (we noemen die personas) voor Pinteresque en maakt het gemakkelijk om ook andere clues te introduceren zoals sport, leeftijd, gezinsvorm, beroep en meer. Pinteresque gebruikt overigens NLP om de kans in te schatten of het te maken heeft met een eigennaam of niet. Als NLU de intent voor naamuitwisseling niet heeft begrepen, wordt NLP ingezet om te achterhalen of er sprake kan zijn van een naam en wordt vervolgens getoetst of dat woord in de voornamenlijst voorkomt.
Pinteresque zal elk binnenkomend slot per persoon onthouden
en mogelijk zelfs gebruiken in het gesprek. Zo kan één van de uit
te spreken teksten zijn: “Mooie naam (her.naam), ik heet
(me.naam)”. Voor de syntax van dit soort teksten is gekozen voor
her. en me. voor respectievelijk de gebruiker –de persoon– en
de robot –persona–.
Als Pinteresque klaar is met een binnenkomend intent, dan zal het tekst uitsturen die met behulp van TTS vertaald wordt naar spraak. ReadSpeaker is een bedrijf dat dit off-line kan, Gepoogd wordt om met ReadSpeaker een schaalbare en inzetbare oplossing te realiseren. Een kwalitatief goed alternatief is de Google Speech API. Als on-line geen bezwaar is, dan is de Google oplossing beperkt CPU-intensief.
De teksten die Pinteresque uitspreekt worden in hetzelfde bestand
opgenomen als de intents. De intents en die reacties staan
onderelkaar, het verschil is dat de reacties voorafgegaan worden
door een + en de verwachtte ontvangen teksten met een -:
## naam uitwisselen:
- Hoi, ik heet (naam)
- Mijn naam is (naam)
- (naam) is mijn naam
+ mijn naam is (me.naam)
+ ik heet (me.naam)
Dit gecombineerde bestand wordt achter de coulissen vertaald naar een aparte bestand voor intents en reacties (aka PIntents en PIntexts).
In figuur 1 zijn de verscheidene onderdelen van de
gespreksbot Pinteresque schematisch weergegeven. Pinteresque (in
rood) past tussen de diverse andere componenten in. Zoals eerder
aangegeven, is een gespreksbot een pipe-line van componenten met
spraak in en spraak uit. Daar waar sprake is van
éénrichtingsverkeer, komt de pipe-line tot
uiting. Ofschoon genoemde figuur de samenhang tussen de al eerder
genomende componenten van een gespreksrobot goed toont, is de
volgende CLI-regel wellicht illustratiever:
asr | nlu | anno | pinteresque | tts
Bovenstaande regel is precies zo te gebruiken in het Pinteresque platform. Fraaier is dat de onderdelen van de pipe-line ook apart gedraaid kunnen worden.
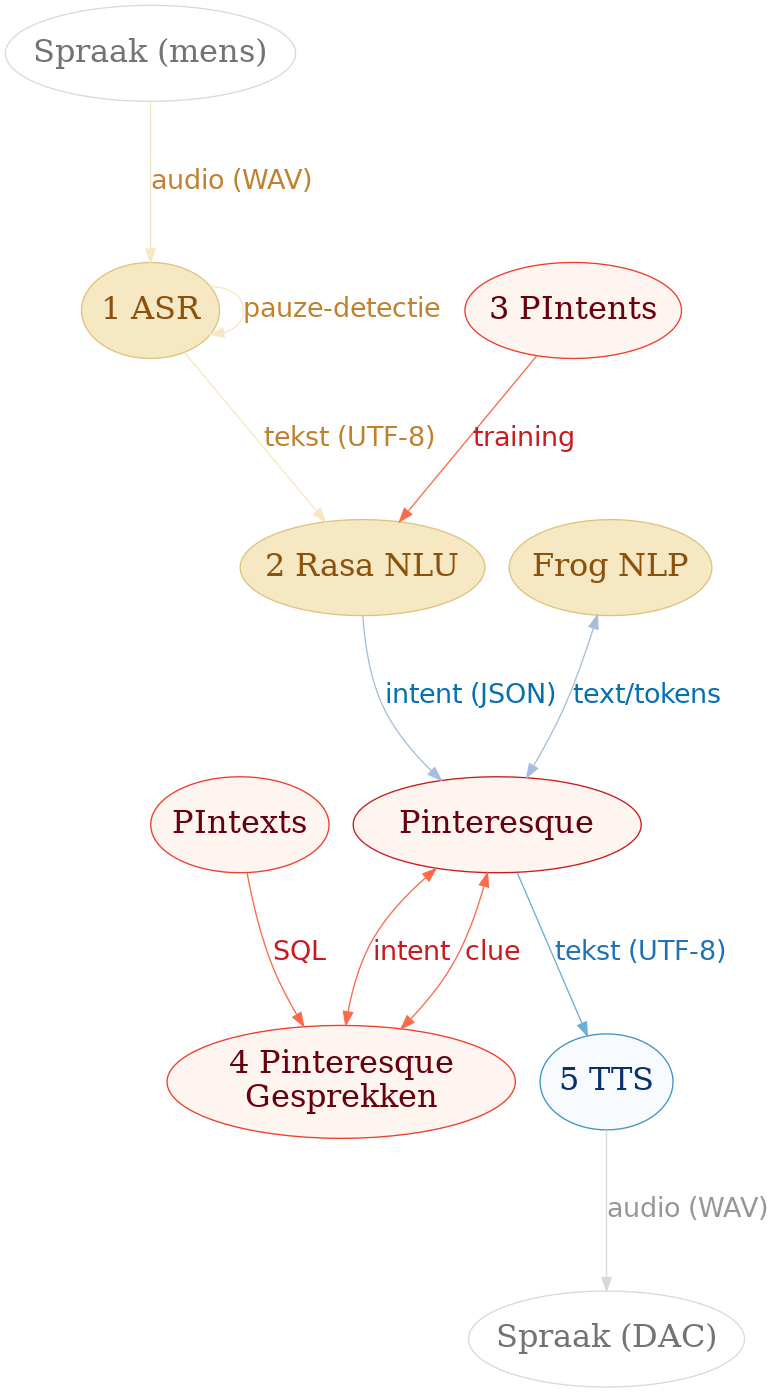
Figuur 1: Abstract beeld van het platform Pinteresque
3.2 Pinteresque is een gespreksbot
Voor een conversational chatbot (in dit document wordt gespreksbot gebruikt) gelden geen wake-words en geen eenvoudige lijst van intents, er wordt gepoogd de binnenkomende tekst te begrijpen. Gehoorde tekst wordt onthouden, om er later op terug te kunnen komen.
3.2.1 Intents: veel of weinig?
Voor Pinteresque is het van belang om zo goed moelijk vast te stellen of het gebruik van enkele tientallen intents wel of niet gaat functioneren. Hiervoor worden interviews gehouden met mensen waarvan de rol door de bot wordt overgenomen.
Voor een intent-analyser (NLU) wordt doorgaans een verzameling reguliere expressies gecompileerd op basis van de complete lijst van intents met slots. Het succes van de intent-analyser hangt af van hoe onderscheidend de intents vanelkaar zijn. Als de verschillen klein zijn, dan wordt analyseren lastig. Er zijn goede intent-engines (Snips, Rasa, zie chatbotsmagazine.com voor een vergelijking). Overlaten aan de applicatie kan ook en zal gebeuren als intent-analyse het af laat weten. In Pinteresque kiezen we voor Rasa (die ondersteunt Nederlands), mogelijk ooit voor een andere NLU-engine.
3.2.2 Geen Wake-word
Een wake-word is acceptabel voor een gespreksbot waarmee in de vorm van commando's wordt gecommuniceerd. In een persoonlijk gesprek wordt dat vermeden.
3.2.3 Tone of voice
Er is veel vernieuwing op het gebied van spraakherkenning; tussen hobby-projecten en wetenschapelijk onderzoek zitten nog talloze initiatieven. Helaas beperkt ASR zich tot het leveren van alleen tekst, annotaties als vraag, stelling, boos ontbreken. Tone of voice als onderzoeksgebied bestaat, maar is nog heel beperkt ontwikkeld. Ook het Nederlandse onderzoeksinitiatief kan niet zeggen of een zin een vraag behelst of een uitroep en zegt niets over de stelligheid van de spreker. Voor een gespreksbot zijn deze meta-gegevens nu juist heel erg belangrijk. Als we gebruik maken van het onderzoek van Arjan, dan is het wellicht mogelijk om in de toekomst wel rekening te houden met tone-of-voice.
Mogelijk kan Frog (de NLP-component in Pinteresque) iets toevoegen aan de analyse, zonder audio te gebruiken. Frog annoteert grammaticaal en kan dus gebruikt worden om stelligheid, herhaling en andere zinsbouw te achterhalen.
Daarnaast zijn er woordenlijsten die gebruikt kunnen worden voor toon en sprekers-perspectief.
3.2.4 Off-line
Pinteresque moet discussies opwekken, maar wel de juiste.
Pinteresque zal geen spraak en tekst delen met de buitenwereld, ook al is de STT en TTS oplossing daardoor minder van kwaliteit of zal de hardware veel duurder zijn (van €120 voor een on-line oplossing naar €1200 voor stand-alone). Een discussie over privacy en het mogelijk meegluren van grote bedrijven doet het narratief van Pinteresque geen goed.
3.2.5 Stilte
Omdat Pinteresque de rol van praatgrage klant (of kapper) speelt, zal stilte na een tijdje, automatisch, worden doorbroken met een vraag. Mits er nog vragen over zijn natuurlijk. Hieronder de waarde van die acceptabele stilte (in vocabulaire van de computertaal GO):
30 * time.Second
Merk op dat de hoeveelheid tijd die gemoeid is met het uitspreken van de tekst er onderdeel van is. Met een acceptabele stilte van 20 seconden en een door de gespreksbot uitgesproken tekst van 10 seconden is de daadwerkelijke toegelaten stilte dus 10 seconden3
3.2.6 Componenten van derden in Pinteresque
3.2.6.1 Microfoon
Stemmen worden opgepikt door één of meer microfoons; arecord is
het GNU/Linux commando dat daarvoor gebruikt wordt. Het levert
een audio-stream aan de ASR. Voor de microfoons zelf is nog geen
voorstel gedaan. De 2-mic HAT die in de Seeed kit zit is een
goede oplossing, maar voor het Omkeerevent 2019 is gekozen voor
een old style telefoon-hoorn. Toen bleek ook dat
noise-cancelling geen overbodige luxe is… die we niet
geïmplementeerd hebben.
3.2.6.2 Opensource Spraakherkenning/Kaldi
Voor de Nederlandse taal is er een hoogwaardig onderzoek gaande aan de TU Twente onder leiding van Dr Arjan van Hessen. ASR en NLU zijn gecombineerd en gebruik (via een API over internet of lokaal: off-line) is vrij.
De gebruikte toolkit is Kaldi, zie ook het kortgeleden geboren initiatief Open Source Spraakherkenning dat een aantal scripts en integratie met Kaldo implementeert voor het NL-model dat via SURFnet beschikbaar is. Dat model is overigens niet Open Source.
De hardware eisen voor het lokaal draaien van een real-time Kaldi platform met Nederlands model zijn: Intel 4-8 core en 32GB RAM.
Arjan (ook Telecats en UU) heeft ondersteuning voor Pinteresque toegezegd en ook hulp bij het verkrijgen van gratis licenties voor het NL-model (de keuze is gemaakt voor het Oral History-model) en ook voor het realiseren van TTS.
Voor Pinteresque zetten we een NUC in met 32GB geheugen en 4 Intel cores. Een dergelijk apparaat zal niet veel meer dan €1200 kosten.
3.2.6.3 Andere spraakherkenning
Gemakkelijk te integreren, maar niet altijd praktisch in gebruik is de Google Cloud Speech API. Zeer veel talen worden begrepen en de uitvoer, tekst dus, is erg goed. Een en ander verloopt alleen on-line.
3.2.6.4 Rasa
Met spraakherkenning op basis van Kaldi, is Rasa een goede optie voor NLU (scoort vergelijkbaar met de Snips NLU-enging). Rasa heeft al Nederlandse modellen en de intent-input bestaat uit eenvoudige markdown files. Na training heeft Rasa daar reguliere expressies en andere modellen van gemaakt, opdat tekst herleid kan worden tot gematchte intents inclusief slot-analyse.
3.2.6.5 Frog
Ofschoon Rasa het aardig doet, stuurt het intents naar de orchestrator zonder kennis over de rol van woorden in de zin. Frog voegt dat toe.
Frog is een server die Nederlandse tekst accepteert en dat vervolgens geannoteerd (elk woord met de rol in de zin) teruglevert. Frog is een Open Source produkt dat onderhouden wordt door Language Machines Research Group en de Center for Language and Speech Technology. De auteurs zijn: Maarten van Gompel, Ko van der Sloot en Antal van den Bosch.
Het is speciaal voor de Nederlandse taal gemaakt.
Pinteresque gebruikt de zgn. PoS TAG zoals gedocumenteerd in POS Manual.
Bedenk dat Frog tussen de drie en vier GB werkgeheugen gebruikt.
Een van de toevoegingen aan Pinteresque als gevolg van de Sorry
Automat is het strippen van onwelkome woorden uit een gematchte
clue. Elke clue heeft zijn eigen set van PoS tags, woorden in
de clue die niet met een van die tags matchen, worden weggehaald
uit de clue. Een eigennaam zal b.v. SPEC als tag hebben. Als de
clue grote Jaap binnenkomt als Rasa-match, dan wordt grote
weggehaald voordat de clue wordt bewaard. Indien eigennaam als
tag: SPEC ADJ heeft, dan wordt grote Jaap bewaard.
3.2.6.6 Tekst naar spraak
Gemakkelijk te integreren, maar niet altijd praktisch in gebruik is de Google Cloud Speech API. Zeer veel talen worden ondersteund en de uitvoer, audio dus, is erg goed. Er wordt per woord afgerekend.
3.2.7 Toepassingen
Er zijn in de loop der tijd diverse toepassingen van Pinteresque ingezet. Niet alleen de kappersklant, maar ook een inboud recruiter en een model dat iemands psychologische profiel met twee onderdelen uitbreidt. Die toepassingen bestaan niet alleen uit een ander model. Zo is de inbound recruiter verstopt in een selection automat, een telefooncel die pas gaat praten met de gebruiker nadat de hoorn opgenomen is; de hoorn ophangen beëindigt het gesprek.
De kappersklant kent een knop voor het activeren van de gespreksbot en andere toepassingen vereisen weer andere triggers voor het starten of juist termineren van het gesprek.
Daarvoor is het side-channel gemaakt. Per toepassing zal het side-channel de input van buiten verschillend oppakken en betekenis geven door commando's naar Pinteresque te sturen. Zie voor de details het side-channel.
3.3 Pinteresque de applicatie
Nadat het probleem van spraakherkenning, pauze-herkenning en intent-analyse is opgelost, wordt de geannoteerde tekst (dat zijn dus de intents) overgedragen aan de applicatie (mogelijk voorafgegaan door grammticale annotatie). Die moet een antwoord kunnen vinden en formuleren op de bedoeling van de tekst die binnenkomt. De intent-analyser levert de tekst dus af bij Pinteresque voorzien van intent-naam en, zo mogelijk, slot-namen en waardes. Daarnaast word aangegeven wat het vertrouwen van de NLU-engine is in het oordeel over intent-naam en slot-namen. Die confidence is een getal tussen 0 en 1. De 1 staat voor heel veel vertrouwen.
Pinteresque, als kappersklant, zal één persoonlijkheid (1 persona) kieze bij aanvang. Wie dat is, wordt bij toeval bepaald. Er kunnen dus meerdere personas, met elk hun eigen verzameling clues (naam, leeftijd etc.) worden ingericht.
Uit het onderzoek blijkt dat het gesprek op de stoel over verscheidene onderwerpen gaat en dat de professional zelf uitzoekt of de klant überhaupt wil praten of niet. De persoonlijkheid die het gesprek uit de weg gaat kan op termijn worden geïntroduceerd, maar in aanvang ondersteunt Pinteresque alleen de spreekgrage klant.
Pinteresque kent niet alleen een eigen rol en één or meer personas, er horen ook clues bij de rol van de gesprekspartner (die van vlees en bloed, de persoon). Tijdens het gesprek probeert Pinteresque clues die nodig zijn voor een uiteindelijk levensecht gesprek, te verzamelen. Niet alle clues hebben dezelfde prioriteit; naam en kennis over de knipwens van de klant staan bovenaan. Er is immers weinig gesprek mogelijk zonder beide in te vullen. Elke persoon in Pinteresque, klant of kapper, kent meerdere clues. Die van de persona in Pinteresque liggen vast, die van de andere partij krijgen gedurende het gesprek vorm.
Twee voorbeelden van personas met clues in Pinteresque worden genoemd in tabel 1, deze zijn voor het model ‘kappersklant’.
| naam | clue | waarde |
|---|---|---|
| christina | dekking | bedekt |
| file | weinig | |
| geslacht | v | |
| haarlengte | halflang | |
| kinderen | 0 | |
| leeftijd | 21 | |
| naam | christina | |
| sport | hockey | |
| studie | communicatiewetenschappen | |
| werk | geen | |
| piet | dekking | vrij |
| file | veel | |
| geslacht | m | |
| haarlengte | kort, maar gedekt | |
| kinderen | 1 | |
| leeftijd | 24 | |
| naam | piet | |
| sport | voetbal | |
| studie | geen | |
| werk | receptionist | |
3.3.1 Abstract beeld van het Orchestrator programma
Het scenario binnenin Pinteresque begint met het kiezen van de persona, het opbouwen van een nieuw persoon en het ontvangen van de ingesproken tekst (mits de bot begint). In figuur 2 staan alle stappen uitgespeld in een scenario-diagram.
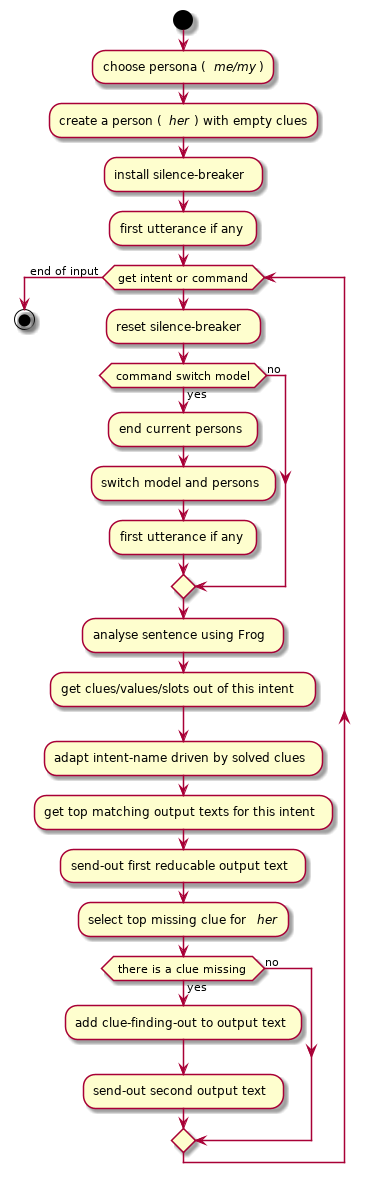
Figuur 2: Pinteresque
3.3.2 Structuur van de dialoog
Omdat Pinteresque het gesprek kan, maar ook moet, sturen, zal het na een reactie op een intent vaak een wedervraag stellen. Dat moeten zit 'm in de beperking van onze gespreksbot; Pinteresque construeert zelf geen zinnen, ze kent een aantal voorziene opmerkingen van de ander en flink wat teksten die daar bijpassen, maar moet dus ook proberen het gesprek daartoe te beperken4.
Voor een goede dialoog is het natuurlijk belangrijk dat de robot weet wat er kort tevoren besproken is. Niet alleen om doublures te voorkomen, maar ook om opgedane kennis, context, later te kunnen gebruiken. Een uitputtende lijst van vragen wordt daartoe opgesteld. Met het concept van clues wordt de context van het gesprek langzamerhand compleet. Een clue staat voor specifieke kennis over een aspect van een persoon. De persona in Pinteresque heeft een flink aantal voorgekookte clues. De persoon start steeds met allemaal niet ingevulde clues. Dat zijn overigens dezelfde clues als die van de persona, op dat gebied is er dus sprake van volledige geljkwaardigheid tussen person en persona.
3.3.3 Een zware last?
Om Pinteresque enigszins begripvol te maken, is een lange lijst van intents, de te herkennen uitspraken van de kapper of kapster, nodig. Enkele honderden is waarschijnlijk wel het minimum. Die intents worden aan de intent-analyser gevoerd als trainingsdata. De getrainde intent-analyser zal real-time teksten omzetten naar intents en de gematchte slots invullen; daarvoor is redelijk wat computer-capaciteit en geheugen nodig. Met onze aantallen zal dat echter geen zware wissel trekken op de hardware.
Daarnaast zijn er reacties en wedervragen nodig: aantal personas × aantal intents × reacties en wedervragen. Al met al redelijk wat data die gemakkelijk toegankelijk moet zijn.
De reacties worden in een relationele database gezet. PostgreSQL wordt daarvoor benut, mede omdat die het meest feature-rijk is als het gaat om gebruik van reguliere expressies en moderne SQL-constructies.
De memory-footprint van PostgreSQL kan beperkt worden en is in ieder geval configureerbaar om enerzijds de complete set van teksten te omvatten en anderszijds de computer niet tot swappen te brengen.
De zwaarste last zit 'm in de ASR; het taalmodel moet in het geheugen passen om veel en trage disk-toegang te voorkomen. 32GB lijkt een bruikbare hoeveelheid geheugen voor de Nederlandse taal. De memory-honger van de andere componenten vallen daarbij in het niet5.
3.3.4 Datamodel: starten, reacties, vragen, wedervragen, antwoorden en afsluiten
Dat Pinteresque put uit een lijst van vragen wordt ingegeven doordat we niet in staat zullen zijn om zelfstandig zinnen te gaan formuleren. Omdat vaak genoemd wordt dat het gesprek tussen kapper en klant enigszins oppervlakkig moet zijn, past dit prima. Daar waar blijkt dat er met regelmaat intieme gesprekken gevoerd worden en af en toe een traantje wordt weggepikt, gaat Pinteresque minder passen.
Dat bij elke vraag een patroon hoort waarmee het kappers-antwoord wordt geanalyseerd maakt een en ander niet per se ingewikkelder. Vervolgens, nu wordt het wat complexer, bepaalt de analyse ervan het vervolg, al of niet over hetzelfde onderwerp.
Dat vervolg bestaat uit twee delen: reactie en volgende tekst. Het zou leuk zijn als een dialoog twee tot drie keer over hetzelfde onderwerp kan gaan. Ook lijkt het mogelijk om een of meer onderwerpen per se aan bod te laten komen. Als de kapper verzuimt te vragen naar hoe het haar geknipt moet worden, dan kan dit, aan het begin, door Pinteresque geadresseerd worden. Dit spiegelgesprek kan natuurlijk ook een vast onderdeel zijn. Het is ook een manier om aan de robot te wennen.
De datastructuren hieronder implementeren het datamodel van Pinteresque en vormt de footprint van de applicatie.
Uitgangspunt van Pinteresque is dat de kapper, een mens, praat met de spraakrobot. Voor elk van die rollen is er een model.
3.3.4.1 Personen (personen en personas)
Telkens als een gesprek begint, wordt er een nieuwe persoon geïntroduceerd; de persoon (de kapper indien Pinteresque kappersklant is, klant als Pinteresque kapper speelt). Daar waar Pinteresque kiest uit de beperkte verzameling eigen personas, zal de mens die Pinteresque gebruikt (of ondergaat) steeds gezien worden als een nieuwe persoon. Afhankelijk van de duur van het gesprek zal die persoon steeds meer vorm krijgen, steeds meer clues zullen worden ingevuld. Het is niet ondenkbaar dat een complete persoon uiteindelijk als persona wordt ingezet voor een nieuw model. De termen persona en persoon worden in dit stuk gebruikt voor respectievelijk de spreekrobot en de mens daarbuiten.
id <<id-type>>, starttime timestamp with time zone default now(),/* beginning of life*/ endtime timestamp with time zone, /* end of life */ isrobot boolean default false, /* is this person a robot? */ model text /* null for any model, otherwise name */
De leef-periode, met begin- en eindtijd, wordt vastgelegd voor
rapportagedoeleinden later. Zo is het goed om te weten hoeveel
clues er per minuut kunnen worden ingevuld en is het ook
interessant om te zien hoe lang gebruikers met Pinteresque
praten. Daarnaast geldt een ontbrekende endtime als een signaal
dat deze persona of persoon actief is. De vlag isrobot geeft
aan of het hier een persona (true) of juist een persoon betreft
(false). Overigens worden persona niet hergebruikt; telkens bij
het laden van een nieuw model, worden de vorige persona
ge-ontrobotiseerd (i.e. isrobot wordt false), en worden nieuwe
persona aangemaakt.
3.3.4.2 Clues
Pinteresque zal proberen om clues te verzamelen. Een gesprek zonder enige kennis van de andere persoon is niet goed mogelijk, die kennis wordt gerepresenteerd door clues. Omdat het bijvoorbeeld heel belangrijk is dat Pinteresque een gesprek in aanvang richt op het overbrengen van de knipwens, kennen clues een prioriteit. Kennis daarover is een van de clues van de kapper. De clue ‘knipwenskennis’ in het model ‘kappersklant’ is er een met een heel hoge prioriteit.
id <<id-type>>, person int references persons(id), /* in case of a clue-instance */ name text, /* name of clue (is an intent slot) */ value text, /* its value */ priority int, /* 0-100, 0 is top prio */ pit timestamp with time zone,/* moment of value assignment */ model text /* the model, can be null for any model */ postags text, /* blank spaced list of POStags to keep in text of value of clue */
Er zijn veel clues ingesteld, daar hangt nog geen persoon aan en daarvan is de waarde nog niet ingevuld, hieronder enkele daarvan:
| name | priority |
|---|---|
| kent knipwens | 0 |
| naam | 0 |
| geslacht | 10 |
| leeftijd | 20 |
| dekking | 20 |
| haarlengte | 20 |
| werk | 30 |
| kinderen | 30 |
Een nieuwe persoon zal alvast ingevuld worden met lege clues. Gegeven bovenstaande –nog niet ingevulde– clues, zal Pinteresque voor deze persoon allereerst op zoek gaan naar een naam en bekendheid met de knipwens. Nadat die zijn ingevuld, wordt er mogelijk over andere dingen gesproken. Gedurende het gesprek ontstaan dus opgeloste clues. De lege clues worden gebaseerd op alle voorheen gebruikte clues. Nieuwe ingebrachte clues worden dus automatisch onderdeel van de volgende persoon.
Voorbeelden van clues voor één van de ingebouwde kappersklanten zijn:
| person-id | clue | value |
|---|---|---|
| 1 | kinderen | 1 |
| 1 | sport | voetbal |
| 1 | dekking | vrij |
| 1 | naam | piet |
| 1 | geslacht | m |
| 1 | leeftijd | 24 |
| 1 | haarlengte | kort, maar gedekt |
| 1 | werk | receptionist |
| 1 | studie | geen |
| 1 | file | veel |
Met deze clues kan Pinteresque antwoord geven op vragen van de persoon.
Clues kunnen daartoe in uitgesproken teksten gebruikt worden. Een basis-tekst ‘Mijn werk als (me.werk) is erg leuk om te doen.’ wordt uiteindelijk uitgesproken als ‘Mijn werk als receptionist is erg leuk om te doen.’
Andersom kan overigens ook. ‘Ja, maar (her.naam), dat kun
je toch voorspellen.’ (her.naam) wordt voor uitspreken vervangen
door de naam-clue van de persoon, de niet-robot.
Bedenk dat clues bewaard blijven en de bijbehorende personen dus
onderwerp van gesprek kunnen worden, het gesprek tussen persona en
persoon gaat dan over een eerdere en andere persoon. In het
oplossen van clues is hiervoor nog geen voorziening (nu zijn de
waardes beperkt tot me. en her.), maar denkbaar is het
wel. Iets als someone.name wellicht.
Personas en personen kennen min of meer dezelfde clues. Niet
helemaal duidelijk is nog hoe de speciale clues te behandelen
zoals ‘kennis over’ de ander. Zo heeft elke persona een knipwens
gezet. Dezelfde clue kan bestaan bij een persoon, maar betekent
dan de wens van die persoon, niet die van de persona. Misschien
kunnen we in de PIntents ook her. en me. gebruiken. Dat breekt
weinig (iets minder voorbeelden per slot, al zal dat reuze
meevallen, want als twee voorbeelden over hetzelfde slot gaan,
maar de ene keer voor de persoon en de andere keer voor de
persona, dan is het eigenlijk niet hetzelfde slot).
3.3.4.3 Teksten
Als automaat doet Pinteresque twee dingen:
- clues oplossen
- gesprek voeren
Voor beide doelen worden teksten ingezet. Die teksten kunnen
referenties gebruiken naar eigen clues (me.<cluename>) en clues
van de ander: her.<cluename>.
Voor het voeren van een gesprek reageert Pinteresque op intents. Voor elke intent (met een eigen naam) zijn er teksten; reacties en vragen.
Voor het trainen van de NLU-engine is het belangrijk dat voor elke intent enkele teksten beschikbaar zijn. Die moeten wel staan voor precies de bedoeling van de spreker, maar verschillend genoeg zijn om de NLU-engine te helpen met het herkennen van veel meer gevallen dan de trainingsvoorbeelden.
In het datamodel voor teksten is een voorziening
richting (direction), matches voor positieve en negatieve
intents en iets met samenhang tussen teksten. Allemaal voor
later.
De meta-data van een tekst kent twee aspecten: de tekst zoals de robot die gaat gebruiken en de intent van de gesprekspartner waarop deze tekst een reactie is. Bij de tekst horen type (vraag of stelling) en de inhoud van de tekst. Bij de intent horen intent en de manier om te toetsen of de intent negatief of positief was. Zo zullen beide vragen ‘je wenkbrauwen niet doen’ en ‘je wenkbrauwen ook’ op dezelfde intent binnenkomen. Voor een goed antwoord is het dus nodig om te weten of er sprake is van ontkenning of niet.6
id <<id-type>>, direction text default 'out', /* in or out, for future use */ type text, /* question or statement aka ? or ! */ intent text, /* intent-name as mentioned in model */ model text, /* name of model used */ content text, /* spoken text, may contain clue-references */ positivematch text, /* regexp for positive emphasis */ negativematch text, /* regexp for negative emphasis */ cluetoinduce text, /* this text induces the other to solve clue-name */ active boolean default true, modifier text /* changes the use of this text */
Voorbeelden van texts zijn:
| intent | content |
|---|---|
| gezin | ik heb er (kinderen) |
| groet | ik heet (naam) |
| groet | mijn naam is (naam) |
| groet | goeiedag (naam) |
| groet | goeiedag |
| groet | hoi ik ben (naam) |
| haarverzorging | weet je hoe ik van dat droge haar afkom? |
| knippen | kort, maar wel gedekt, graag |
| knippen | oren graag vrij |
| verkeer | had jij last van het verkeer vandaag? |
Het intent-model wordt opgeschreven in een markdown-bestand met een beperkte syntax. Ofschoon die syntax formeel niet goed is vastgelegd, is het wel laagdrempelig. Voor de teksten wordt ook voor markdown gekozen. De conversie naar de database gebeurt tijdens installatie en darna steeds opnieuw nadat het bestand wijzigt.
Het oplossen van clues in de teksten gebeurt op een manier die
vergelijkbaar is met de manier waarop slots in het model worden
ingevoerd. In de tekst worden ( en ) gebruikt om aan te geven
dat de tekst ertussenin moet worden gebruikt als naam voor de
clue. De waarde ervan wordt dan ingevuld, de tekst is daarna
opgelost. Er is in een gespreksprake van twee personen, dus ook
van twee verzamelingen clues: de ene wordt voorafgegaan door me.
en de ander door her..
Overigens is me. de default indien weggelaten.
Personas worden tevoren gemaakt als onderdeel van het model.
3.3.4.4 Eigennamen
Geslacht is een van de clues om op te lossen. Voor een gesprek kan het van belang zijn om te weten of de ander een man of een vrouw is. Natuurlijk zijn er ook allerlei andere vormen dan deze twee, maar voor het gesprek in de stoel van de kapper lijkt het redelijk om ons tot deze twee te beperken.
Een truc om te achterhalen of Pinteresque met een man of vrouw te maken heeft is het gebruiken van de voornaam. Die wordt in het gesprek uitgewisseld en kan worden opgezocht in een daarvoor beschikbare lijst die duidelijkheid schept over het geslacht.
Een lijst van veelvoorkomende voornamen wordt gebruikt om de intents te verbeteren, deze kan ook worden gebruikt om het geslacht te achterhalen.
id <<id-type>>, name text, sex text
Deze truc helpt, maar is niet feilloos natuurlijk. De namen in tabel 2 kennen zowel ‘m’ als ‘v’ als geslacht:
| name |
|---|
| aike, aissa, alex, aydan, amel, amal, amine, anjo, alexis, ali, a… |
| bouke, bobby, brett, bauke, billie, bartje, bente, bobbie, brecht… |
| casey, chris, cameron, ceylan, charley, camille, charel, cyrille,… |
| dante, devi, daniek, danique, darcy, demi, dewi, danny, demy, des… |
| elif, esra, eliza, elian, erin, ezra, esli, eelke, elisa, eef, el… |
| francis, finn, florian, floor, feike, farah, fatih… |
| guus, gerry, germaine, gillian, gaby, gerrie, gwen… |
| hanne, hong, hajar, ho, hamdi, hani, hylke, hoang, hayat, hanan, … |
| ischa, ingmar, ilham, imme, ike, ilya, ikram, iza, isa, ilja, ilk… |
| jantje, josé, jans, jean, jacey, jaime, jess, juul, jia, jay, jo,… |
| kay, kaya, kai, kayra, kaoutar, kelly, kim, kes, kris, kylian, ka… |
| lucca, lois, lesly, loran, lauren, luca, leslie, lee, levi, len, … |
| maron, maxim, misha, marijn, myron, misja, michal, matty, maria, … |
| nana, nevin, najat, nermin, nikky, nikita, noa, nur, nikola, noah… |
| ouissam, oussama… |
| pieke, patrice, pascal, pinar, pim, pasquale, puk, pleun, puck, p… |
| quincy, quincey, quinn… |
| rayan, robin, riley, rim, rian, rowan, remi, renée, ruth, remy, r… |
| sem, skye, sasha, sascha, shannon, soufiane, sam, si, sultan, sil… |
| tonny, ted, thanh, teddy, terry, taylor, teun, tamar, tjarda… |
| wing, wan, willy, wendel, wai, wen, wei, wissam, willie… |
| xiao, xin… |
| yaël, yoni, yaniek, yentl, yin, yke, yori, yael, yi, yoshi, yassi… |
| zoë, zakaria, ziggy, zefanja… |
3.3.4.5 Trail
Om meerdere redenen willen we bijhouden wat er gebeurt. Binnen een spreek-sessie kan bekeken worden of een tekst al eerder door de robot gebruikt is, dat kan dan vermeden worden. Daarnaast is de trail van belang voor rapportage die gebruikt wordt voor verbetering van de spraakbot.
Bij elk uitsturen van tekst wordt de tekst van de intent die er aan voorafging opgeslagen, samen met de persona en persoon en natuurlijk welke (indien aanwezig) clue er gepoogd wer op te lossen en welke tekst er verstuurd werd.
id <<id-type>>, pit timestamp with time zone default now(), intentname text, persona int references persons(id), person int references persons(id), pintext int references texts(id), intent jsonb, output text
Merk op dat er referenties gebriukt worden naar de personen, teksten en clues. Dat heeft snelheid en beperkte footprint als voordeel, maar het niet kunnen verwijderen van teksten, clues en persons als nadeel. Voor clues en personen is dat geen probleem, er is geen noodzaak om die ooit weg te gooien. Maar voor teksten geldt dat ze niet persoons-gebonden zijn en soms vervangen worden door verbeterde verzamelingen intents. De oude worden dan op non-actief gezet en kunnen nog steeds onderdeel uitmaken van gespreks-rapportage.
3.3.4.6 DDL en versie Postgresql
Het type voor een id is generated by default as identity.
Maar helaas ondersteunt de nieuwste Postgresql
versie op Rasbian (9.6) dat niet. Dus wordt het in dat geval een
minder effectieve oplossing:
serial primary key
int primary key generated by default as identity,
3.3.5 Informatie-primitieven
Pinteresque heeft continu informatie nodig over de volgende stap, de status van de clues en zo meer. Er is geprobeerd zoveel mogelijk van het oplossen van die informatievraag in de RDBMS op te lossen.
Een poging wordt gedaan om de de tabellen uit de database af te
beelden op de bijbehorende struct in Go, met eensluidende
kolomnamen danwel attributen. Marshalling en un-marshalling kan
dan zonder veel omhaal.
Daarnaast leveren de queries zo vaak mogelijk één enkele regel op. Daardoor zijn for-loops maar heel beperkt in de code aanwezig7.
De informatiebehoefte (zowel lezen als schrijven) van Pinteresque
wordt in de onderstaande primitieven gedefinieerd. Je vindt ze terug
in het scenario (zie 2) en in de code van de
diverse persistency packages: onder meer die van persons,
clues en texts.
[X]get any persona; Deze primitieve begint met het ophalen van een willekeurige persona. Het maakt Pinteresque niet uit waarmee het begint, als het maar een persoon is die de rol van persona speelt.
select p.id, p.starttime, p.endtime, p.isrobot, p.model from persons p where p.isrobot and (p.model is null or p.model = ?) order by p.model, random() limit 1
De
order by random()draagt zorg voor de willekeur, delimit 1voor het ophalen van één enkele persona.Daarna wordt die persona gestart; dat is niet meer dan het zetten van de starttijd en het uitpoetsen van de eindtijd. Bedenk dat personas steeds weer hergebruikt worden.
update persons set starttime = now(), endtime = null where id = ?
Bedenk dat
start-personamogelijk iets wijzigt aan de persoon, die specifieke persoon moet vervolgens worden opgehaald.[X]get a specific person; Onderstaande query is bedoeld voor personas en personen.
select p.id, p.starttime, p.endtime, p.isrobot, p.model from persons p where p.id = ?
Merk op dat we de implementatie van rollen in de database verbergen door een
JOINte doen.[ ]een Clue kent de context van een model. Indien dienullis, dan geldt ie voor alle modellen.[ ]Er komen clues bij, dat kan door gebruik van nieuwe PIntents met niet voorziene slots. Die worden automatisch aan de persoon in kwestie toegevoegd en daarna, bij nieuwe personen, automatisch in hun lege-clues-lijst gezet. De clues-lijst van de personas zou ook uitgebreid moeten worden.[X]get a new person; enkele SQL-statements zijn nodig. Een nieuwe persons-row wordt ge-insert en voor dat id, nieuwe clues. Die clues zijn copieën van bestaande clues:
De nieuwe persoon is een insert, met daarna de query om de nieuwe inhoud op te halen:
insert into persons ( starttime, endtime, model ) values ( now(), null, ? ) returning id
Vervolgens worden voor deze persoon de clues geïnitialiseerd. Er is geen vaste verzameling van niet-ingevulde-clues. We putten uit alle clues die voor de persona ingevuld zijn en voegen die aan de persoon toe, maar dan nog niet ingevuld.
insert into clues (person,name,value,priority,model,postags) select ?, name, null, max(priority), ?, max(postags) from clues c where (model is null OR model = ?) and person in (select id from persons where isrobot and coalesce(model,'') = coalesce(c.model,'') order by id DESC limit 1) group by name
We intitialiseren een persoon met alle mogelijk clues voor het model, mits die in gebruik zijn bij personas. Het predicaat daarvoor is personen onder een bepaalde maximum
id, maar dat is niet blijvend. Beter is om te kijken naar clues van recente personas. Mogelijk verdwijnt hetidnamelijk als manier om personas te vinden8.(person < 10)
[X]fill in missing clues for a person; ofwel, gegeven een of meerdere clues, maak die persistent voor her. Gegeven de persoon, clue-naam en clue-waarde, zal dit een update oid. worden.
update clues set value = ?, pit = now() where id = ?
Meestal wordt een clue bewaard gegeven de waarde, naam en persoon. Een
updatezal niet altijd slagen, soms wordt er een clue gevonden die niet voorzien is. Daarvoor wordt dan eeninsertgedaan. Helaas is er geenupdate ... on error do insert ...en beginnen we met eeninsert, het minst voorkomende scenario. Als de clue al bestaat, maar niet ingevuld is, dan mislukt deinsertvanwege de eis dat het tuple( name, person, model )(die constraint heetclues_un) uniek moet zijn. Deon conflictvan deinsertvoert dan de bedoelde update uit.insert into clues ( value, name, person, pit, model ) values ( ?value, ?name, ?person, now(), ?model ) on conflict ON constraint clues_un do update set value = ?value, pit = now() where clues.value is null
Merk op dat we een eenmaal ingevulde clue nooit opnieuw invullen. Merk ook op dat de
updatealleen plaatsvindt op de (name,person)-combinatie waarmee deinsertinsteekt. Dewhere-clause van de update heeft dus een implicieteand name=<the-name> and person=<the-person>toegevoegd9. mer daarnaast op dat het model geen rol speelt bij een bewaarde clue. De clue is het resultaat van het gesprek en hoort bij de persoon die daarnaa nooit meer hergebruikt wordt.10[X]get text by content; Sommige standaardteksten worden op basis van de inhoud opgehaald. Die teksten moeten in de database aanwezig zijn, anders faalt de bot. Het gaat dan om stoplappen als “hm”, “sorry, ik begrijp je niet”.
select * from texts t where t.content = ? and (t.model is null OR t.model = ?) and t.active order by t.model, random() limit 1
Per model kan er een andere standaardtekst gebruikt worden. Niet helemaal duidelijk is hoe dit zit??? Het lijkt onzin om per model een tekst te hebben die precies eensluidend is voor alle modellen. Voorlopig gelden teksten zonder model ook als te gebruiken, maar dan als er geen andere zijn.
[X]top matching output texts; met als parameter: intentid, persona-id. Deze query retourneert de mogelijke reacties op een intent. Omdat een intent afsluitend kan zijn over een onderwerp en omdat het aantal teksten voor die intent op kan zijn, worden er ook teksten toegevoegd die niet vragend zijn en niets te maken hebben met deze intent. Die worden dan achteraan gesorteerd en komen dus alleen aan de beurt indien de intent-gerelateerde teksten op zijn.
with ttheq as ( with theq as ( <<matching-sql>> limit 10) select id, direction, type, intent, model, content, positivematch, negativematch, cluetoinduce, active, modifier from theq order by ordering, p limit 5) select id, direction, type, intent, model, content, positivematch, negativematch, cluetoinduce, active, modifier from ttheq
select t.id, t.direction, t.type, t.intent, t.model, t.content, t.positivematch, t.negativematch, t.cluetoinduce, coalesce( (select priority from clues where name = t.cluetoinduce and person = ?person), 0 ) as p, t.active, t.modifier, 1 as ordering from texts t where <<texts-for-this-intent:intent,model>> and t.active and coalesce(modifier,'') != '<<to-start-with>>' and coalesce(modifier,'') != '<<to-finish-with>>' and coalesce(modifier,'') != '<<to-byebye-with>>' and t.direction = 'out' and (not <<used-texts:persona,person>> or coalesce( t.modifier, '' ) in ('<<do-repeat>>', '<<last-resort>>') ) and not <<solved-clues:person,model>> UNION <<intents-solving-a-clue:clue,model>> UNION select t.id, t.direction, t.type, t.intent, t.model, t.content, t.positivematch, t.negativematch, t.cluetoinduce, coalesce( (select priority from clues where name = t.cluetoinduce and person = ?person), 0 ) as p, t.active, t.modifier, 4 as ordering from texts t where <<texts-for-not-this-intent:intent,model>> and t.active and coalesce(modifier,'') != '<<to-start-with>>' and coalesce(modifier,'') != '<<to-finish-with>>' and coalesce(modifier,'') != '<<to-byebye-with>>' and t.direction = 'out' and (not <<used-texts:persona,person>> or coalesce( t.modifier, '' ) in ('<<do-repeat>>', '<<last-resort>>') ) and not <<solved-clues:person,model>> UNION select t.id, t.direction, t.type, t.intent, t.model, t.content, t.positivematch, t.negativematch, t.cluetoinduce, coalesce( (select priority from clues where name = t.cluetoinduce and person = ?person), 0 ) as p, t.active, t.modifier, 5 as ordering from texts t where <<texts-for-not-this-intent:intent,model>> and t.active and coalesce(modifier,'') = '<<to-finish-with>>' and coalesce(modifier,'') != '<<to-byebye-with>>' and t.direction = 'out' and (not <<used-texts:persona,person>> or coalesce( t.modifier, '' ) in ('<<to-finish-with>>') ) and not <<solved-clues:person,model>> order by ordering, p
(replace-regexp-in-string " \\?" " the" " <<matching-sql>> ")
create or replace function toptexts( theperson int, thepersona int, theclue text, themodel text, theintent text ) returns table(id int, direction text, type text, intent text, model text, content text, positivematch text, negativematch text, cluetoinduce text, p int, active boolean, modifier text, ordering int ) as $$ <<thesqlwithparams()>> $$ language 'sql';
We zouden ook kunnen selecteren op text-en met daarin
oplosbare clues, de GO-code test dat nu zelf en verwerpt
een text als die clues refereert die nog geen waarde
hebben. Dat kost echter wel wat matching, substrings, regexps en
ander complex SQL-gedoe. Een groot voordeel van een complexere
query zou zijn dat de limit 5 dan kan naar limit 1
en er dan een for-loop is gesaneerd.▮
Daarnaast zouden we de teksten, als er een intent-mismatch is en
daardoor geen teksten meer over zijn, aanvullen met teksten die
horen bij de intent die de meest recente clue heeft opgelost.
Als iemand een functienaam noemt, die als clue opgelost wordt, maar
met de intent voor b.v. eigennaam. Dan wordt de text bij de intent
functienaam-noemen nooit gebruikt. Die van eigennaam wel, maar die is
waarschijnlijk al uitgeput. Het kan dan essentieel zijn om met
UNION een select toe te voegen die zoekt op de text die
hoort bij de intent die naam oplost.▮
select t.id, t.direction, t.type, t.intent, t.model, t.content, t.positivematch, t.negativematch, t.cluetoinduce, 5 as p, t.active, t.modifier, 3 as ordering from texts t where t.intent = (select intent from texts it where it.active and coalesce( it.modifier, '' ) != '<<to-start-with>>' and it.direction = 'in' and it.model = ?model and it.cluetoinduce = ?clue group by intent order by count( intent ) DESC LIMIT 1) and t.model = ?model and t.active and t.direction = 'out' and (not <<used-texts:persona,person>> or coalesce( t.modifier, '' ) in ('<<do-repeat>>', '<<last-resort>>') )
We zoeken teksten die bij een gegeven intent en model horen. De conditie daarvoor is:
(t.intent ilike ?intent and t.model = ?model)
Daaraan worden de teksten toegevoegd die juist niet bij de gegeven intent horen, maar wel in dit model zitten.
(not t.intent ilike ?intent and t.model = ?model)
Er wordt vermeden om teksten te selecteren die clues oplossen die al opgelost zijn:
(replace( replace( cluetoinduce, 'her.', '' ), 'me.', '') in (select name from clues where person = ?person and (model is null or model = ?model) and not value is null))
Merk op dat voorkomen wordt dat er eerder uitgesproken teksten worden gebruikt door teksten die al in de trail voor dit gesprek opgenomen zijn te vermijden:
(t.id in (select distinct coalesce(pintext,0) from trail where persona = ?persona and person = ?person) )
De tweede and conditie is om ervoor te zorgen dat herhaalbare
pintexts toch opnieuw gebruikt worden. Die komen dan als niet
gebruikt terug.
Er wordt een with (aka CTE) gebruikt omdat de ordening binnen
de eerste en tweede set random moet zijn, maar wel met de eerste
set eerst. Die kolommen mogen echter niet in het resultaat
getoond worden, het automatisch marshall/unmarshall mechanisme
in GO probeert die kolommen dan in de tabel te vinden met falen
als gevolg. De limit 5 had ook op de CTE kunnen worden gedaan,
maar is naar binnen getrokken om performance redenen.
[X]start text; sommige modellen laten de gespreksbot beginnen met praten. De startteksten kennen daarvoor een modifier.
select * from texts where model = ? and active and modifier = '<<to-start-with>>' order by random() limit 1
[X]going away text; sommige modellen laten de gespreksbot beginnen met praten. De startteksten kennen daarvoor een modifier.
select * from texts where model = ? and active and modifier = '<<to-byebye-with>>' order by random() limit 1
[X]clue; gegeven een persoon en een clue-naam, retourneer de clue.
select * from clues where person = ? and name = ? and (model is null OR model = ?) limit 1
[X]top clue; gegeven de persoon, de clue met de hoogste prioriteit die nog niet is ingevuld:
select * from clues where person = ? and model = ? and value is null order by priority limit 1
De text die bij het achterhalen van de clue hoort is dan iets als:
select t.id, t.direction, t.type, t.intent, t.model, t.content, t.positivematch, t.negativematch, t.cluetoinduce, t.active, t.modifier from texts t where t.active and t.direction = 'out' and replace( replace( t.cluetoinduce, 'her.', '' ), 'me.', '') = ? and t.model = ? order by random() limit 1
[X]Een tekst kan referenties bevatten naar clues. Dat gebeurt met een simpele syntax:
([<source>.]<cluenaam>).De
<source>.is optioneel en kanme.zijn voor de persona enher.voor de persoon.me.is impliciet.In de GO-code testen we het iets eenvoudiger, omdat we alleen maar willen weten of er een clue-ref is. Als er een of meer letters, cijfers of punten tussen haakjes staan, dan is er sprake van een clue referentie:
\\((me.|her.|)[a-z0-9]+\\)
was
\\([a-z0-9\\.]+\\)De reguliere expressie die een clue-referentie in SQL matcht is daarom:
(?:(\(((her.|me.|)\w+)\))+){1,1}Bij gebruik in de SQL functie
regexp_matcheskomt er bij deze reguliere expressie twee resultaten terug: de clue-naam met haakjes en zonder. De eerste (text-to-replace) wordt gebruikt om te vervangen door de waarde (de haakjes verdwijnen dus), de tweede (clue-name) voor het zoeken in de clues.(select regexp_matches(content, '<<regexp-for-clueref>>'))[1]
(select regexp_matches(content, '<<regexp-for-clueref>>'))[2]
Het vervangen van de referenties door de bijbehorende waarde wordt vervolgens met SQL opgelost. Zo kun je het eerste te reduceren veld uit een text voor de persona 1 en persoon 38 reduceren met:
select content, <<clue-name>> as "clue-name", replace( content, <<text-to-replace>>, case when <<clue-name>> like 'her.%' then (select value from clues where name = replace(<<clue-name>>,'her.','') and person = 38) else (select value from clues where name = replace(<<clue-name>>,'me.','') and person = 1) end ) as result from texts where content like '%(%)%' order by 2
content clue-name result doe jij nog iets naast je werk als (her.beroep)? her.beroep mooie naam (her.naam). Ik heet (me.naam) her.naam mooie naam karel. Ik heet (me.naam) mooie naam (her.naam) her.naam mooie naam karel ik ben werkzaam als (me.beroep) me.beroep ik heb er (me.kinderen) me.kinderen ik heb er 1 hoi ik ben (naam) naam hoi ik ben piet goeiedag (naam) naam goeiedag piet mijn naam is (naam) naam mijn naam is piet ik heet (naam) naam ik heet piet De code die dit aanroept kan in een for-loop net zolang doorevalueren totdat de text niet meer wijzigt, of leeg is. Leeg houdt in dat er een clue gereduceerd is zonder waarde.
select replace( ?content, <<go-pg-text-to-replace>>, case when <<go-pg-clue-name>> like 'her.%' then coalesce((select value from clues where name = replace(<<go-pg-clue-name>>,'her.','') and person = ?person and model = ?model), <<go-pg-text-to-replace>>) else coalesce((select value from clues where name = replace(<<go-pg-clue-name>>,'me.','') and person = ?persona and model = ?model), <<go-pg-text-to-replace>>) end ) as result limit 1
Overigens ben ik er van overtuigd dat dit mooier en sneller kan met een of meer
with-statements en eenjoinoverclues.[ ]set and unset finding-this-clue; niet zeker is of dit persistent moet zijn, kan ook in Pinteresque worden beheerd. Het bewaren in de database heeft weinig waarde; na een restart zal Pinteresque toch deze clue weer kiezen om op te lossen.
Ondertussen kent een Text-object ook de, mogelijk afwezige, clue-naam die gevonden gaat worden na uitspreken. De clue-to-induce. Als het vorige uitgesproken text-object nog bekend is, dan zal oplossen van die clue in de gehoorde tekst voorrang moeten krijgen.
[X]add to trail; een log van inserts op de tabel trail met iets als:
insert into trail (persona,person,pintext,intentname,intent,output) values (?persona,?person,?pintext,?intentname,?intent,?output)
De trail zal ook gebruikt worden voor het uitsluiten van de al gebruikte teksten.
[X]current-person; Als Pinteresque in een lopend gesprek wordt uitgezet (of wanneer iemand de stroomkabel er uit loopt), dan gaat dit gesprek na starten door waar het ophield. Het enige dat nodig is voor dat herstarten is de persona en de persoon. Voor de persoon geldt:
select p.id, p.starttime, p.endtime, p.isrobot, p.model from persons p where p.endtime is null and not p.isrobot order by p.starttime DESC limit 1
De running persona is dan:
select p.id, p.starttime, p.endtime, p.isrobot, p.model from persons p where p.endtime is null and p.isrobot order by p.starttime DESC limit 1
[X]end-person; een gesprek en ook een knipbeurt komt op een gegeven moment teneinde. Dat luidt ook het einde van de persoon in, voor zover die bij Pinteresque bekend is. Het invullen van de endtime is voldoende om dit te realiseren:
update persons set endtime = now() where id = ? and endtime is null returning id, starttime, endtime, isrobot, model
Merk op dat de
endtimealleen overschreven worden indien die null is. Dat is om te voorkomen dat multipledefer()'s leiden tot personen die na modelwisselingen nogmaals worden opgeruimd. De eerste keer opruimen is altijd de bedoelde.▮[X]guess-gender; achterhaal, gegeven de naam, welk geslacht daar mogelijk bijhoort.
select sex from names where name ilike ? order by random() limit 1
Zoals hierboven te zien is wordt bij namen met meer dan een enkel geslacht, een toevalskeuze gemaakt.
[X]update-gender; achterhaal, gegeven de naam, welk geslacht daar mogelijk bijhoort.
update clues set value = (select sex from names where name ilike ?name order by random() limit 1) where person = ?person and name = 'geslacht' and coalesce(value,'') = ''
Zoals hierboven te zien is wordt bij namen met meer dan een enkel geslacht, een toevalskeuze gemaakt.
[X]person-to-report-for; kort na het einde van een gesprek willen we rapportage leveren over dit gesprek (onder meer voor supervised learning). We zoeken dan naar de persoon die korter dan 20 seconden geleden een gesprek beëindigde dat langer dan 4 gespreks-regels duurde. Het vinden van die persoon kan met:
select p.id, p.model from trail t JOIN persons p ON t.person = p.id where ( not p.endtime is null and p.endtime > (CURRENT_TIMESTAMP - interval '20 second')) or p.id = @param<pid> group by p.id, p.endtime, p.model having count(t.*) > 4 order by p.endtime DESC limit 1
[X]the-trail; de meest recente gesprekken worden hiermee gevonden en op een manier gepresenteerd waarmee er naar de gesproken teksten kan worden gekeken.
select p.id, max(pit) as pit, to_char( max(pit) - min(pit), 'mi:ss' ) as duration, (select coalesce( value, '<tbd>') from clues where person = p.id and name = 'naam') as naam, (select coalesce( value, '30') from clues where person = p.id and name = 'leeftijd') as leeftijd, (select coalesce( value, '<tbd>') from clues where person = t.persona and name = 'naam' and model = p.model) as persona, count(intentname) filter (where intentname like '%pos%') as p, count(intentname) filter (where intentname like '%neg%') as n, count(intentname) filter (where intentname like '%herhalen%') as h, string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) as tt from trail t JOIN theperson p ON p.id = t.person group by p.id, t.persona, p.model having length( string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) ) > 10 order by max(pit) DESC limit 20
id pit duration naam leeftijd persona p n h tt 608 2019-06-16 13:09:28.992302+02 05:11 Post 55 Patricia 0 0 6 geen probleem ja als zo vuldig en serieus stappen voor wat Ja gewoon hier toegekomen klaar Post 55 honderden mensen aannemen en dat was ontzettend ingewikkeld Dat was toch best lastig Ja kom maar op moest mensen bij elkaar brengen die tegenover elkaar stonden en dat goed begeleid ja als een beetje een Drammer denk ik Het kan me echt helemaal niks rijden Dat kan me niks schelen Dat kan me niks schelen How Waarom ga je nou praten Patricia Hoe kan dat nou uitkomen Waarom moet hij melding nu turnen turnen en dit [X]get-the-metrics;
select thetrail.persona, thetrail.naam, thetrail.leeftijd, thetrail.duration, thetrail.id, to_char( thetrail.pit, 'HH24:MI') as tm, 1.0*(select count(*) + 1 from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d) where d in <<reporting-intrinsic>>) / (select count(*) + 1 from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d) where d in <<reporting-extrinsic>>) as R, p, n, h, (select '"'||words.d||'" '||count(*)||' keer' as stopword from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d) where length(d) > <<reporting-stopwordlen>> group by d order by count(*) DESC limit 1) as stopwoord from thetrail
3.4 Pinteresque, implementatie per onderdeel
3.4.1 Lijstje van TODO's
3.4.1.1 open
[ ]JH opties voor texttospeech commando, inclusief -v e.d.[ ]JdV parse de gegeven intents van 18 juni en integreer die in het model voor ir-bot.[ ]JH volgorde moet wat beter kunnen worden gestuurd in het model.[ ]JH drop de awk/shell-renew parsing en doe het in Go. Is meer portable, sneller en gemakkelijker uit te breiden.[ ]JH gebruik de end-pintext ook als er op end gedrukt wordt via het sidechannel.[ ]JH als een intent een slot (clue) oplevert dat niet bij die intent hoort, dan kan de pintext bij die intent aangevuld worden met de intent die dat slot levert. Dat verbetert de intent-match en voegt in het model manieren toe om het intent-matchen te verbeteren.[ ]JH gesprek beëindigen met een uitsmijter indien de clues op zijn. Clues op is belangrijk, overigens is het aantal gematchte clues een clue! De uitsmijter kan met een $ of zo aangegeven worden. Er kan een low-watermark geformuleerd worden voor het aantal clues dat over mag zijn, alvorens de $-pintext gebruikt wordt.[ ]JH overweeg of dit tool gebruikt kan worden voor het invullen van formulieren. Daar lijkt het nl. heel erg geschikt voor.[ ]besteedt de metrics uit aan iemand anders.[ ]vervang de unix pipe-lines door Go pipelining, is portable. Zie ook: https://blog.golang.org/pipelines. Dit kan voor asr, nlu, anno, pinteresque en tts. Ook voor het sidechannel natuurlijk. Begin met NLU, dan side-channel en ANNO. TTS kan ook. ASR is lastig vanwege de herstartende google speech context. Test eerst of er geen serieuze performance issues zijn. Met b.v. een wordcount programma dat lezen en tellen in andere threads doet.[ ]zonder frog gaat het herkennen van getallen, met name leeftijden, mis. Dat komt doordat het token dat je uit de sentence trekt dan leeg is. isNumber levert dan natuurlijk nee op. Frog is essentieel en gebruikt 3Gb. Op een Pi 3 draait ie b.v. niet.[ ]met ctrl-c laat je persons achter zonder endtime! defer helpt niet. stuur vanuit nlu een end-command, dat werkt wel. Maar niet zeker is dat die eerder komt dan de ctrl-c. Die moet gehandled worden. Kill ook.[ ]bijhouden van scores uit woordenlijsten (mbt gespreksperspectief en zo) gebeurt in clues. De rapportage kan daar gebruik van maken.[ ]de microfoon gaat niet snel genoeg weer aan na het uitspreken van een tekst. Dat moet sneller. Mogelijk kan wijzigen van deaplaysource code versnelling brengen. Het zou m.i. een optie vooraplaymoeten zijn. Daarnaast kan de output gebruikt worden voor echo-cancellation op input. Dan hoeft de microfoon niet uitgezet te worden.[ ]Silence-breaker kickt te snel in, zie de tekst: Merk op dat de hoeveelheid tijd die gemoeid is met het uitspreken van de tekst er onderdeel van is. Met een acceptabele stilte van 20 seconden en een door de gespreksbot uitgesproken tekst van 10 seconden is de daadwerkelijke toegelaten stilte dus 10 seconden.
Dat kan opgelost worden door er tijd bij op te tellen afhankelijk van de lengte van de tekst. De bot merkt nl. niet op dat de TTS nog praat, de bot is direct klaar met uitspreken. De reset-silence-breaker kan natuurlijk na de laatste output, maar dat is niet goed genoeg. de lengte van de tekst speelt ook een rol.[ ]naamgeving memberfuncties moet indicatie geven over find/save/state etc. personsGender b.v. is een state of een database-zoekactie of zoeken met enige kans op succes ipv 100%?[ ]intents met max confidence minder dan 0.2 oid. (configureerbaar?) moeten worden genegeerd. De gespreksbot kan dan nl. altijd meeluisteren en alleen een gesprek starten indien er iets relevants gebeurt. Er moet dan een start-intent bestaan![ ]minderif's inmain()en geenlog.Printf's, doe die lager, dan wordtmain()goed leesbaar en lijkt 100% op het schematische Pinteresque.[ ]als je langer dan 20 seconden praat, dan kikt de silence-breaker in en wordt je niet alleen onderbroken, maar wordt de tekst (deels?) weggegooid, de microfoon gaat namelijk even uit. Omzeilen met uitlokken korte antwoorden?[ ]maak eenannotatefilter tussen NLU en Pinteresque in die Frog-analyse doet en als json-attributes toevoegt aan de NLU-json. Daarmee neemt hoeveelheid code van Pinteresque in main() af en is het eenvoudiger om los van de componenten, intelligentie toe te voegen aanannotate. De JSON Rasa-container kan dan uitgebreid worden met eenAnalysis-component.[ ]voeg een intent toe voor last-resort, om de dialoog gaande te houden, indien geen intent herkend wordt. Bij het selector model kan iemand een lang antwoord geven, dat zeker niet matcht met een intent. Dat moet herkend worden. Vervolgens kunnen we negatieve of positieve classificaties tellen, lengte van het antwoord en vragen naar meer detail mbt een speciaal onderwerp. Die onderwerpen zijn natuurlijk situatie, taak, aanpak en resultaat. Allemaal clues![ ]krijg de Kaldi-installatie zo ver dat ie functioneert en de on-line Google STT kan vervangen.[ ]NK maak een WEB-interface voor editten van modellen of iig uploaden van een nieuw model.[ ]NK maak een WEB-interface voor uitproberen van modellen met alleen tekst in en uit.[ ]op basis van afgehandelde intents, re-prioriteren van intents die binnenkomen. Zo is naam op een gegeven moment afgehandeld, het komt echter voor dat een intent abusievelijk toch als naam wordt gelabeled. Daarmee wordt dan de bedoelde intent gemist. Als b.v. na oplossen van naam-clue, een naam-slot of naam-clue-oplossend intent binnenkomt, de confidence verlagen met 0.2 of een factor 0.8.[ ]Welke clue hangt in de lucht wordt nog niet geïmplementeerd. De intent die binnenkomt kan een direct antwoord zijn op een vraag, een PIntext, die een clue oplost. Een poging zou moeten worden gedaan om voor die clue het slot te vinden. Zeker als het antwoord maar een enkel woord is (b.v. “ja”). Die>her.<clue>zou, ook al is de intent niet herkend, toch gezet moeten worden. Deze is belangrijk voor intents die meerdere clues op kunnen leveren.[ ]nu leert Pinteresque clues vanzelf aan, maar er kan nog meer geleerd worden. Ik zou graag, gedurende het gesprek, PIntents automatisch toevoegen aanpintents.md.
3.4.2 Het model
Een beschrijving van het model wordt vastgelegd in een markdown-bestand met de naam van het model. In figuur 13 een voorbeeld voor de gespreksbot als kappersklant. Een model bestaat uit namen van intents, de te matchen ontvangen teksten voor die intents, uit te spreken reacties mbt die intents, de pintexts en clues. De clues definieren de personas en worden gebruikt als informatiebehoefte over de personen.
Er is steeds sprake van een intent-naam, verwachte tekst en uit te
spreken tekst. De intent-naam wordt aangegeven met
## intent:<naam>. NLU zal na herkenning van de tekst die bij deze
intent-naam hoort, deze naam aan de applicatie doorgeven. De
teksten die daarvoor getraind worden, zijn die die met een
-
beginnen. Omdat NLU de Nederlandse taal kent zal het meer
herkennen dan precies deze teksten.
De teksten die met een
+
beginnen, zijn bedoeld om door de
gespreksbot uitgesproken te worden als reactie op de intent die
binnenkomt. Deze teksten heten pintexts.
De pintexts kunnen beginnen met modifiers die niet gecombineerd worden:
,*– deze pintext mag herhaald worden.&– deze tekst wordt alleen gebruikt als er geen andere meer zijn, implicieert*. Dit soort pintexts worden in dedefault-intent gebruikt.@– deze tekst wordt gebruikt als starttekst, modellen waar de gespreksbot als eerste spreekt gebruiken één enkele tekst met deze modifier. Ook als de bot niet als eerste spreekt is het verstandig om met iets als “uhm” te starten.
De reguliere expressie die deze modifier matcht is:
^[*&@%~!=%]
Er is een bijzondere intent, die kan gebruikt worden als een manier om niet herkende intents op te pakken. De NLU zal soms geen intents, of misschien een paar intents met heel lage betrouwbaarheid, signaleren. De teksten onder de default-intent kunnen dan gebruikt worden.
Naast intents worden ook clues gedefinieerd. De clue-naam wordt
aangegeven met ## clue:<naam> met daarachter regels met
prioriteiten en waardes (respectievelijk p en v). Zie hiervoor
paragraaf Syntax van de modellen.
Er zijn bijzondere clues:
- naam – hiermee wordt de eigennaam van een persona of persoon bedoeld. In het modelbestand start die een nieuwe persona en Pinteresque zal bij het matchen van deze clue een tabel met Nederlandse eigennamen (voornamen) gebruiken als hulp en als manier om de clue geslacht te bepalen.
- lastoutput – een persona met deze clue zal de laatst uitgesproken tekst hierin steeds opslaan.
- lastinput – een persona met deze clue zal de meest recente gehoorde, ontvangen, tekst hierin steeds opslaan.
Net als andere clues, kunnen deze speciale clues in pintexts gebruikt worden.
Ofschoon Pinteresque gemaakt is om de kappersklant te simuleren, kan het om het even welk model gebruiken. Het model voor kappersklant blijft echter wel de default, voor het geval er niets is ingevuld.
3.4.2.1 De Kappersklant
## intent:groet - hallo. - hi. - hai. - goedemorgen. - goedenavond. + goeiedag. ## intent:naam - hoi ik ben [patty](naam) - hoi ik heet [gerard](naam) - hai ik ben [maria](naam) - hi ik ben [moniek](naam) - hi ik heet [patricia](naam) - mijn naam is [eduardo](naam) - [goedemorgen](dagdeel), ik heet [maria](naam) - [goedemiddag](dagdeel), ik heet [maria](naam) - [goedenavond](dagdeel), ik heet [karin](naam) + mooie naam, (her.naam). Ik heet (naam). + hoe heet jij? >her.naam + wat is je naam? >her.naam ## intent:knippen - hoe wil je dat ik je knip? - hoe wil je geknipt worden? - hoe wil je je haar hebben? + kun je me ongeveer hetzelfde knippen als nu? maar dan korter. >her.kent knipwens + zo'n beetje (haarlengte). >her.kent knipwens ## intent:knippenoordekking - wilt je de oren [gedekt](dekking) houden? - oren [gedekt](dekking)? - oren [vrij](dekking)? - wilt je de oren [vrij](dekking) houden? - wilt je je oren [vrij](dekking)? - wilt je de oren [gedekt](dekking)? + oren graag (dekking), maar niet te opvallend. >her.kent knipwens ## intent:knippenlengte - wil je [lang](haarlengte) haar? - wil je [kort](haarlengte) haar? - wil je [halflang](haarlengte) haar? + (haarlengte), graag, of ietsje langer, mag ook >her.kent knipwens ## intent:knipopdrachtbevestiging - [ok](kent knipwens), [halflang](haarlengte) en oren [vrij](dekking) [dus](kent knipwens) - [ok](kent knipwens), oren [vrij](dekking) en [halflang](haarlengte) [dus](kent knipwens) - [lang](haarlengte) en oren [gedekt](dekking) [dus](kent knipwens) - oren [vrij](dekking) en [lang](haarlengte) [dus](kent knipwens) - oren [vrij](dekking) en [kort](haarlengte) [dus](kent knipwens) - je wil [dus](kent knipwens) [lang](haarlengte) en oren [gedekt](dekking) - je wil [dus](kent knipwens) oren [gedekt](dekking) en [lang](haarlengte) + doe maar, inderdaad. + helemaal goed hoor. ## intent:kappersprodukten - heb je nog iets nodig als shampoo of gel - je weet dat we haarverzorgingsartikelen van hoge kwaliteit verkopen + heb je iets tegen van dat droge haar? + twee flessen shampoo graag. ## intent:reistijd - moet je van ver komen - had je lang reizen - hoe ver, enkele reis + een uur enkele reis. ## intent:hobby - ik [teken en schilder](hobby) af en toe - ik [naai kleren](hobby) voor vrienden en kennissen - ik doe aan [dansen](hobby) + heb jij nog een hobby? >her.hobby + knippen is vast je lust en je leven, maar doe je er nog iets naast? >her.hobby + ik ben klaarover op school ## intent:sport - ik speel [voetbal](sport) - ik speel [hockey](sport) - ik speel [volleybal](sport) - ik doe aan [cricket](sport) - [cricket](sport) - [la crosse](sport) - doe jij aan sport - welke sport doe jij + ik speel (me.sport) + wat voor sport doe jij? >her.sport + ik (me.sport) + doe je ook aan sport? >her.sport ## intent:verkeer - was het gemakkelijk te vinden - was het makkelijk te vinden - had je [een beetje](verkeersdruk) file vanmorgen - had je [veel](verkeersdruk) file vanmorgen - had je [veel](verkeersdruk) file - was er [veel](verkeersdruk) file + ik had (file) file; had jij last van het verkeer vandaag? >her.file + ik had (file) file hoor ## intent:leeftijd - [30](leeftijd) - ik ben [42](leeftijd) - [18](leeftijd) jaar + ik ben (me.leeftijd) + mag ik vragen hoe oud je bent? >her.leeftijd ## intent:pinty-internal - robot stop. - robot quit. + ok, doe ik ## intent: de-weg-kwijt - snap je het niet @ hm + sorry, ik begrijp je niet ## clue:naam p 0 v piet ## clue:geslacht p 10 v m ## clue:leeftijd p 20 v 24 ## clue:werk p 30 v receptionist ## clue:studie p 50 v geen ## clue:dekking p 20 v vrij ## clue:haarlengte p 20 v kort, maar gedekt ## clue:kinderen p 40 v 1 ## clue:file p 40 v veel ## clue:sport p 30 v voetbal ## clue:naam p 0 v christina ## clue:geslacht p 10 v v ## clue:leeftijd p 20 v 21 ## clue:werk p 30 v geen ## clue:studie p 50 v communicatiewetenschappen ## clue:dekking p 20 v bedekt ## clue:haarlengte p 20 v halflang ## clue:kinderen p 40 v 0 ## clue:file p 40 v weinig ## clue:sport p 30 v hockey
Bovenstaand bestand wordt automatisch omgezet naar een pintent-model met training voor NLU en pintexts, personas en clues in de database voor gebruik door Pinteresque.
3.4.2.2 Werving en Selectie
Voor het Omkeerevent op 18 juni 2019 in de Metaalkathedraal worden twee vacatures gebruikt: Inbound Recruiter en HR Manager. Eerst de inbound recruiter met de versie waarbij de bot begint met praten.
De vast te stellen competenties zijn: assertief, luisteren, doelgericht, positieve houding, open vragen.
;;; bot zou ook naam werkgever moeten noemen, praten is pluggen ## intent:begin + @Hoi, wat fijn dat je er bent en welkom op ons hoofdkantoor. ik hoop dat\ je het een beetje hebt kunnen vinden?>her.verkeersissues ## intent:verkeerok - ja hoor dat is [gelukt](verkeersissues) - dat ging [prima](verkeersissues) - ja hoor [prima](verkeersissues) - zeker dat ging [vanzelf](verkeersissues) - ja hoor [geen probleem](verkeersissues) - ja hoor [geen file](verkeersissues) - dat ging [goed](verkeersissues) - [ja hoor](verkeersissues) dat ging wel goed - [ja](verkeersissues) + Mooi zo. Je komt hier solliciteren op positie (me.vacature), allereerst\ wil ik je wat praktische vragen stellen. daarna volgen wat uitgebreidere\ vragen. Hoe spreek je je voornaam precies uit?>her.naam ## intent:verkeernietok - nou ik vond het toch [lastig](verkeersissues) - ik was even de weg [kwijt](verkeersissues) maar vond hem toch weer - ik had wat [file](verkeersissues) - [nou](verkeersissues) ik was wel de weg kwijt in het gebouw - dat ging [niet helemaal](verkeersissues) goed + Nou, gelukkig dat je er toch bent gekomen. Je komt hier solliciteren op\ positie (me.vacature), allereerst wil ik je wat praktische vragen stellen.\ daarna volgen wat uitgebreidere vragen. Hoe spreek je je\ voornaam uit?>her.naam ;;; veel manieren om een naam over te brengen, voorlopig alleen voornamen ## intent:naam - ik ben [patty](naam) - ik heet [gerard](naam) - ik ben [maria](naam) - [moniek](naam) - [geurt](naam) heet ik - ik heet [patricia](naam) - mijn naam is [eduardo](naam) - ik heet [maria](naam) - ik heet [mark](naam) - ik heet [karin](naam) - met [jolanda](naam) - als [jaap](naam) + Ok, (her.naam). En wat is je leeftijd?>her.leeftijd ;;; het is mij niet duidelijk of en hoe ik (leeftijd) moet opsplitsen in (leeftijdpos) en (leeftijdneg) ## intent:leeftijdpos - ik ben [32](leeftijd) - [21](leeftijd) jaar ben ik - mijn leeftijd is [19](leeftijd) - [jong](leeftijd) genoeg zou ik zeggen - [23](leeftijd) jaar oud - [28](leeftijd) + Ok, dat is goed om te weten, ik kon het niet terugvinden op je CV. Mijn\ naam is (me.naam), (me.afdeling), met mij zul je te maken krijgen mocht\ je hier in dienst komen, en ik ben ook het eerste aanspreekpunt binnen\ het sollicitatietraject. Ben je klaar voor de volgende vraag?>her.wilgesprek ## intent:leeftijdneg - [45](leeftijd) is mijn leeftijd - [dat](leeftijd) zeg ik liever niet - [45](leeftijd) - [laten we zeggen](leeftijd) boven de 50 - [61](leeftijd) jaar - inmiddels ben ik [50](leeftijd) - [jong genoeg](leeftijd) zou ik zeggen + Ok, dat is goed om te weten, ik kon het niet terugvinden op je CV. Mijn\ naam is (me.naam), (me.afdeling), met mij zul je te maken krijgen mocht\ je hier in dienst komen, en ik ben ook het eerste aanspreekpunt binnen\ het sollicitatietraject. Ben je klaar voor de volgende\ vraag?>her.wilgesprek ## intent:leeftijdneg - ik weet niet waarom [leeftijd](leeftijd) relevant zou zijn - waarom wil je mijn [leeftijd](leeftijd) weten + Ook goed. Ik kon het niet terugvinden op je CV. Mijn naam is (me.naam),\ (me.afdeling), met mij zul je te maken krijgen mocht je hier in dienst\ komen, en ik ben ook het eerste aanspreekpunt binnen het\ sollicitatietraject. Ben je klaar voor de volgende vraag?>her.wilgesprek ;;; heb hier een tweede vraag aan toegevoegd. ## intent:klaarvoor - [ja](wilgesprek) ik ben er klaar voor - [ja](wilgesprek) hoor - [ja](wilgesprek) hoor kom maar op - [zeker](wilgesprek) - [goed](wilgesprek) - [OK](wilgesprek) + OK, vertel eens over een situatie waarin er een hoge werkdruk was en\ je achter liep op schema?>her.situatie1 + Beschrijf een situatie in het verleden waarin jouw sterke communicatie\ skills het verschil maakte in een project of opdracht>her.situatie1 ;;; veel meer intents hiervoor, eentje gaat niet werken! ;;; denk dat de tweede vraag niet opgelost gaat worden met de clues in (situatie1) ## intent:klaarvoorniet - [nee](wilgesprek) nog niet ik had nog een vraag - [nee](wilgesprek) kan ik nog iets vragen - kan ik [nog](wilgesprek) iets vragen + Zullen we vragen tot het einde bewaren? Vertel eens over een situatie\ waarin er een hoge werkdruk was en je achter liep op schema?>her.situatie1 + Zullen we vragen tot het einde bewaren? Kun je me vertellen over een\ situatie waarin je feedback kreeg die je niet had verwacht?>her.situatie1 ## intent:drinkennogeens - Nee, zou ik nog even wat [water](drinken) mogen halen - Nee, zou ik [wat](drinken) mogen + Vooruit dan maar. Vertel eens over een situatie waarin er een hoge\ werkdruk was en je achter liep op schema?>her.situatie1 + Beschrijf een situatie in het verleden waarin jouw sterke communicatie\ skills het verschil maakte in een project of opdracht>her.situatie1 ## intent:antwoordsit1 - dat was in [2016](periode) toen we voor een tweede maal bezig waren\ met een [reorganisatie](situatie1) - in [2018](periode) hadden we een project lopen voor een klant waarvoor\ veel [externe expertise](situatie1) nodig was, het was toen lastig\ tijdig de juiste kennis aan te trekken. - dat gebeurt eigenlijk [nooit](situatie1), dat ik achter liep op schema - net voor de [zomer](periode) hadden we opeens een [personeelstekort](situatie1),\ waardoor het team overuren moest draaien - voor een opdrachtgever moesten we in één keer 100 [posities vullen](situatie1),\ het was heel lastig om dat nog binnen dat kwartaal de juiste mensen aan te trekken. + Hoe heb je dat toen aangepakt?>her.taak1 + Ok, dat is helder. Een andere vraag. Hoe zou je je eigen rol binnen een team\ beschrijven?>her.competentie1 ## intent:antwoordtk1 - ik heb het team [aangestuurd](taak1), zodat zij de juiste lijntjes\ uit konden gooien - ik heb veel [vacatures uitgezet](taak1) om zo onze outreach te vergroten - ik heb [HR](taak1) gevraagd bij te springen - ik heb het doorgespeeld aan [human recourses](taak1) - onze [manager](taak1) heeft ingegrepen - ik heb gekeken waar nog [capaciteit](taak1) beschikbaar was om de drukte\ op te vangen - ik ben heb in [samenspraak](taak1) met Human Resources gekeken of er toch\ niet een mouw aan konden passen - ik heb meerdere mensen [verantwoordelijk gemaakt](taak1) voor de sourcing\ van personeel - door de assessment te [automatiseren](taak1) + Waarom heb je ervoor gekozen het op die manier aan te pakken?>her.taak1waarom + En als je er over nadenkt, hoe zouden jouw collega's je\ beschrijven?>her.competentie1 ## intent:argumententaak1 - ik denk dat het belangrijk is [snel te schakelen](taak1waarom) in dit soort\ situaties - omdat [goed overleg](taak1waarom) zeer belangrijk is - omdat [afstemmen](taak1waarom) zeer belangrijk is - omdat ik denk dat dit in het team het [beste werkt](taak1waarom) - omdat dit zorgt dat we voldoende mensen aantrekken zonder\ meer [uren te schrijven](taak1waarom) - omdat dit een [duurzame](taak1waarom) oplossing is voor dit probleem - [zorgvuldige](taak1waarom) overwegingen speelden een rol + Wat was het resultaat?>her.resultaat1 + En als je er over nadenkt, hoe zouden jouw collega's je\ beschrijven?>her.competentie1 ## intent:resultaat1noemen - het resultaat was dat we binnen het kwartaal [weer bij](resultaat1) waren - dat alles was op tijd [klaar](resultaat1) - dat mensen meer [ontspannen](resultaat1) konden werken - dat er aanzienkelijk [minder stress](resultaat1) was op de werkvloer - dat we onze [targets](resultaat1) toch gehaald hebben - dat we uiteindelijk toch een [tevreden](resultaat1) klant hadden - dat we toch de juiste [selectie](resultaat1) hebben kunnen maken - het [resultaat](resultaat1) was goed + Kun je me een voorbeeld geven van een lastig keuzeproces bij het aannemen\ van een kandidaat?>her.keuzeproces + Ok, dat is helder. Een andere vraag. Hoe zou je je eigen werkwijze\ beschrijven?>her.competentie2 ## intent:keuzeprocesuitleggen - we hadden toen een [geschikte](keuzeproces) kandidaat maar de manager vond\ haar niet geschikt - ik moest toen kiezen of ik iemand nog op de valreep wilde\ [aannemen](keuzeproces) - het gesprek was goed maar de [assessment](keuzeproces) liet hele andere\ resultaten zien - ik moest toen kiezen of ik iemand nog op de valreep wilde\ [aanstellen](keuzeproces) - ik had toen [te weinig](keuzeproces) kandidaten - in feiten was er niet echt een [keuze](keuzeproces), ik moest het gewoon\ zien te verkopen intern + Welke stappen heb je precies ondernomen?>her.stappen2 + Ok, ik schrijf het even op. Hum, nog een andere vraag, hoe zou je je eigen\ professionele houding beschrijven?>her.competentie2 ;;; zou zoiets werken? ## intent:competentie1pos - ik ben vrij [uitgesproken](competentie1) - ik ben wat meer [extravert](competentie1) - ik ben vrij [vriendelijk](competentie1) - ik ben vrij [goedaardig](competentie1) - ik ben vrij [assertief](competentie1) - ik ben tamelijk [charismatisch](competentie1) - ik ben tamelijk [enthousiast](competentie1) - ik ben tamelijk [gezellig](competentie1) - ik ben tamelijk [overtuigend](competentie1) - ik ben tamelijk [zelfverzekerd](competentie1) - ik ben tamelijk [spraakzaam](competentie1) + Ok, dat kunnen we wel gebruiken in deze functie, goed om te weten! hoe zou je\ je eigen professionele houding beschrijven?>her.competentie2 ## intent:competentie1neg - ik ben vrij [introvert](competentie1) - ik ben wat meer [tot mezelf](competentie1) - ik ben vrij [voorzichtig](competentie1) - ik ben vrij [gereserveerd](competentie1) - ik ben vrij [alleen](competentie1) - ik ben tamelijk [reflecterend](competentie1) - ik ben tamelijk [gereserveerd](competentie1) - ik ben tamelijk [gevoelig](competentie1) - ik ben tamelijk [verlegen](competentie1) + Ok, dat hoeft natuurlijk geen probleem te zijn. hoe zou je je eigen professionele\ houding beschrijven?>her.competentie2 ## intent:competentie2pos - ik ben [Actief](competentie2) - ik ben [Ambitieus](competentie2) - ik ben [Voorzichtig](competentie2) - ik ben [creatief](competentie2) - ik ben [Precies](competentie2) - ik ben [nieuwsgierig](competentie2) - ik ben [logisch](competentie2) - ik ben [georganiseerd](competentie2) - ik ben [perfect](competentie2) - ik ben [perfectionistisch](competentie2) - ik ben [nauwkeurig](competentie2) + %Dit spreekt van zelfkennis, dat is altijd goed om te horen. Ok, (her.naam),\ dat waren mijn vragen. Hartelijk dank voor je tijd. Als je de hoorn zo ophangt\ zie je meteen de uitkomsten van deze assessment. En je weet meteen of we je\ uitnodigen voor een volgende ronde. Plak de resultaten zichtbaar op, zodat\ onze human recruiters je kunnen herkennen. ## intent:competentie2neg - ik ben [bezorgd](competentie2) - ik ben [zorgeloos](competentie2) - ik ben [ongeduldig](competentie2) - ik ben [lui](competentie2) - ik ben [stijf](competentie2) - ik ben [ongefocust](competentie2) - ik ben [sober](competentie2) - ik ben [ongedisciplineerd](competentie2) - ik ben [ongeconcentreerd](competentie2) - ik ben [onstabiel](competentie2) - ik ben [instabiel](competentie2) + Ah, dat is wel een heel eerlijk antwoord. Ok, (her.naam), dat waren mijn\ vragen. Hartelijk dank voor je tijd. Als je de hoorn zo ophangt zie je na\ 15 seconden de uitkomsten van deze assessment. En je weet meteen of we je\ uitnodigen voor een volgende ronde. Plak de resultaten zichtbaar op, zodat\ onze human recruiters je kunnen herkennen. ## intent:noemtstappen2 - ik heb eerst gekeken of de [competenties](stappen2) van de kandidaat voldoende\ aansloten, ook al waren er maar twee kandidaten, daarna heb ik het overlegd\ met de team manager - ik heb gekeken welk [budget](stappen2) beschikbaar was voor het vullen van\ deze positie - ik heb gekeken of we middels interne [training](stappen2) het gebrek aan\ specifieke hard skills kunnen aanvullen met onze interne expertise - ik heb [contact opgenomen](stappen2) met de juiste mensen - ik heb [afgestemd](stappen2) met het team - naar aanleiding van een aantal [star](stappen2) vragen konden we de kandidaten\ beter vergelijken - ik heb gekeken naar de beste [match](stappen2) tussen de functiebeschrijving en\ de kandidaten + Waarom heb je voor deze aanpak gekozen?>her.waaromstappen ## intent:noemtwaaromstappen - om zo [draagvlak](waaromstappen) te creëren voor mijn keuze - omdat er [weinig keuze](waaromstappen) was, we moesten met deze kandidaat verder - ik denk dat die het beste resultaat gaf voor de klantbeleving\ van de [kandidaat](waaromstappen) - om zo iedereen [mee te nemen](waaromstappen) in te proces - om zo de [competenties](waaromstappen) gemakkelijker te kunnen testen - om zo mijn keuze beter te kunnen [verantwoorden](waaromstappen) - om zo mijn keuze beter te kunnen [verkopen](waaromstappen) + Wat was het resultaat?>her.resultaat2 ## intent:noemtresultaat2 - dat we toch op tijd iemand hebben kunnen [aantrekken](resultaat2) om het\ project te starten - dat we [helaas](resultaat2 één van de deliverables niet op tijd konden opleveren - dat we toch externe expertise moesten [inhuren](resultaat2), waardoor we\ één van de deliverables niet op tijd konden opleveren - het resultaat was dat we de kandidaat toch konden [aannemen](resultaat2), zij\ werkt hier nog steeds - het resultaat was [onenigheid](resultaat2) in het team + En, ben je hier tevreden over?>her.tevreden2 ;;; als dit de afsluitende intent is, is deze dus heel belangrijk? kan die ;;; automatisch geintroduceerd worden worden op een of andere manier? # intent:bentevreden - ja zeker, ik denk dat we het beoogde [resultaat](tevreden2) wel hebben gehaald - nou ik vind wel dat het [beter](tevreden2) had gekund - nou nee, ik heb wel geleerd wat ik de volgende keer [anders](tevreden2) ga doen - [zeker](tevreden2) tevreden - [nee](tevreden2) niet zo erg - [ja](tevreden2) erg tevreden - [absoluut](tevreden2) zeker weten + %Ok, (her.naam), dat waren mijn vragen. Hartelijk dank voor je tijd. Als je de\ hoorn zo ophangt zie je na 15 seconden de uitkomsten van deze assessment. En je\ weet meteen of we je uitnodigen voor een volgende ronde. Plak de resultaten\ zichtbaar op, zodat onze human recruiters je kunnen herkennen. ## intent:herhalen - watte - [nog eens](herhaling) - kun je dat [herhalen](herhaling) - kun je dat [nog eens zeggen](herhaling) - wat zei je - wat zeg je - ik heb het niet goed [verstaan](herhaling) - ik heb het niet helemaal [gevolgd](herhaling), zou je dat kunnen herhalen - zou je dat in [andere woorden](herhaling) uit kunnen leggen - wat was dat [laatste](herhaling) + (me.lastoutput) + ik herhaal (me.lastoutput) ## intent:de-weg-kwijt - snap je het niet - uhm - begrijp je wat ik bedoel + *sorry, ik begrijp je niet, kun je dat op een andere manier omschrijven? + *hum, ok, kun je daar iets meer over vertellen? + *en wil je daar verder nog iets aan toevoegen? ## clue:naam p 0 v Harald ## clue:geslacht p 10 v m ## clue:leeftijd p 5 v 31 ## clue:functie p 100 v medewerker pz ## clue:afdeling p 100 v human resources ## clue:vacature p 100 v inbound recruiter ## clue:verkeersissues p 8 v ja ## clue:wilgesprek p 10 v ja ## clue:werkgever p 100 v Jansen en ko ## clue:drinken p 40 v koffie ## clue:lastoutput p 100 v uhm ## clue:lastinput p 100 v uhm ## clue:situatie1 p 15 v placeholder ## clue:taak1 p 18 v placeholder ## clue:taak1waarom p 20 v placeholder ## clue:resultaat1 p 24 v placeholder ## clue:keuzeproces p 31 v placeholder ## clue:competentie1 p 28 v placeholder ## clue:competentie2 p 34 v placeholder ## clue:positiekandidaat p 28 v placeholder ## clue:stappen2 p 34 v placeholder ## clue:waaromstappen p 38 v placeholder ## clue:resultaat2 p 44 v placeholder ## clue:tevreden2 p 48 v placeholder ## clue:naam p 0 v Patricia ## clue:geslacht p 10 v v ## clue:leeftijd p 5 v 31 ## clue:functie p 100 v medewerker pz ## clue:afdeling p 100 v human resources ## clue:vacature p 100 v inbound recruiter ## clue:verkeersissues p 8 v ja ## clue:wilgesprek p 10 v ja ## clue:werkgever p 100 v Jansen en ko ## clue:drinken p 40 v koffie ## clue:lastoutput p 100 v uhm ## clue:lastinput p 100 v uhm ## clue:situatie1 p 15 v placeholder ## clue:taak1 p 18 v placeholder ## clue:taak1waarom p 20 v placeholder ## clue:resultaat1 p 24 v placeholder ## clue:keuzeproces p 31 v placeholder ## clue:competentie1 p 28 v placeholder ## clue:competentie2 p 34 v placeholder ## clue:positiekandidaat p 28 v placeholder ## clue:stappen2 p 34 v placeholder ## clue:waaromstappen p 38 v placeholder ## clue:resultaat2 p 44 v placeholder ## clue:tevreden2 p 48 v placeholder
3.4.2.3 De Sorry Automat
Bedenk dat deze installatie eigen opgenomen stemmen gebruikt voor
de pintexts (de met + gemarkeerde teksten). Dat kan door de
hashes te gebruiken waarmee de text-to-speech dienst wordt
gecached. Na caching kan de .wav-file vervangen worden door de
bedoelde opname. De tekst in het model kan dus afwijken van wat
er daadwerkelijk gezegd wordt.
## intent:begin + @waarvoor zou jij nog excuses willen ontvangen?>her.naam ## intent:naam - ik ben [patty](naam) - ik heet [gerard](naam) - ik ben [maria](naam) - hallo ik ben [patty](naam) - hallo ik heet [gerard](naam) - hallo ik ben [maria](naam) - hoi ik ben [joost](naam) - hoi ik heet [marijke](naam) - hoi ik ben [mohammed](naam) - ik heet [doryn](naam) - mijn naam is [doryn](naam) - [dorian](naam) - [moniek](naam) - [daphne](naam) - [myrthe](naam) - [rozemarijn](naam) - [geurt](naam) heet ik - [moniek](naam) is mijn naam - mijn naam is [myrthe](naam) met een m - ik heet [patricia](naam) - mijn naam is [eduardo](naam) - ik heet [maria](naam) - ik heet [mark](naam) - hallo ik heet [karin](naam) - hallo met [jolanda](naam) - als [jaap](naam) - hallo [piet](naam) hier + Goed, fijn dat je hier bent.\ Vertel eens, waarvoor zou je nog excuses willen ontvangen?>her.waarvoor ## intent:waarvoor - al die keren dat mensen je [overhalen om nog even te blijven](waarvoor) ja dat - van een [goede vriendin](wie) met wie ik [backpackte](wat) die me een [half uur uitschold](waarvoor) - ik zou graag excuses willen ontvangen voor al mij [dateleed](waarvoor) die lopen vaak vrij slecht af - toen hoorde ik ineens helemaal [niets meer](waarvoor) van hem - nou mijn moeder had me [niet uitgenodigd op haar verjaardag](waarvoor) - ik ben [uitgescholden](waarvoor) - een winkel heeft de [spullen niet geleverd](waarvoor) - ik ben [ontslagen](waarvoor) - voor een [te late terugbetaling](waarvoor) - voor de [botsing](waarvoor) - ik werd [aangereden](waarvoor) - iemand [bekraste mijn auto](waarvoor) - ik zou nog wel excuses willen ontvangen van [tessa](wie) omdat zij dat [podium](waar) de [lak niet droog](waarvoor) was - voor de mevrouw die van de week zei dat ik [niet op de stoep mocht fietsen](waarvoor) terwijl ik minder ruimte inneem - ik kreeg een [klap in mijn gezicht](waarvoor) - iemand heeft me [dronken gevoerd](waarvoor) - voor de [botsing](waarvoor) - eh, van [mijn baas](wie) omdat opeens soort van heldere hemel dat er [geen ruimte meer is](waarvoor) voor ontwikkeling - Eh, gewoon. We hadden vlak daarvoor een [beetje ruzie gehad](waarvoor), dus misschien dat het daardoor komt? - Voor het [missen van de trein](waarvoor). + Wat vervelend zeg! Kun je me daar nog iets meer over vertellen?>her.meer1 + Kun je mij vertellen wat dit met jou deed?>her.aangedaan ## intent:aangedaan - al die keren dat voelt gewoon - het [geeft een gevoel](aangedaan) dat ik me [schuldig voel](gevoel) [om weg te gaan](wat) - dat ik een beetje [uit mijn kracht wordt gehaald](aangedaan) - een beetje [pissig](gevoel) en ik kan ook mezelf voor de kop slaan omdat ik [onvoorzichtig ben](rol) - ik werd er een [beetje boos](gevoel) van want ik [voelde me onbegrepen](aangedaan) - ik denk dat ik er [onzeker](aangedaan) van werd - ik voelde me [heel verdrietig](aangedaan) want het was heel gezellig - ik schrok ervan en was er door [van slag](aangedaan) - mijn toekomstperspectief was aan het [wankelen](aangedaan) gebracht - Ja, veel [gedoe](aangedaan), geld kwijt en heel veel verdriet - Waar moet ik beginnen [veel pijn](aangedaan) - Wat ik zeg, een [hoop ellende](aangedaan) + En als je nou echt eerlijk tegen jezelf bent, wat voor gevoel gaf dit jou?>her.gevoel ## intent:gevoel - voor mezelf voelt het [een beetje slap](gevoel) - ja [boos](gevoel) [licht pissig](gevoel) eigenlijk [geirriteerd](gevoel) - dat ik mij [onbegrepen voelde](gevoel) - een gevoel van [onzekerheid en minderwaardigheid](gevoel) denk ik - [verdrietig onzekerheid](gevoel) want je ben zo oninteressant - dat wil ik liever niet zeggen eh [verraden](gevoel) - iets als een [klap in het gezicht](gevoel) - ik vind het [stom](gevoel) - ik voelde me [niet gezien](gevoel) - ja ik was eerst [boos](gevoel) daarna verdrietig - (nijdig)[gevoel] werd ik - flink (pissig)[gevoel] natuurlijk - ja eerst [geschrokken](gevoel) daarna boos - Je voelt je [machteloos](gevoel) en boos tegelijk + Dat snap ik wel. Kun je nog voor mij herhalen wie dat precies deed?>her.wie ## intent:wie - [heel veel mensen](wie) - [tessa](wie) - dat was een [onbekende mevrouw](wie) met een hondje uit de buurt - een [jongen](wie) die ik via tinder heb leren kennen - mijn [moeder](wie) dus - het was [Jaap](wie) die het deed - De [Bijenkorf](wie) was ervoor verantwoordelijk - mijn [neef](wie) deed het - het was [de winkel](wie) - nou dat eh was [mijn broer](wie) - natuurlijk [Agnes](wie) die doet dat soort dingen - de [portier](wie) denk ik - ja dat was [mediamarkt](wie) + Waarom heeft diegene dat gedaan, denk je?>her.waarom ## intent:waarom - omdat ze het [gezellig](waarom) vinden dat [je blijft](wat) - ik denk niet dat [ze](wie) het [expres](waarom) heeft gedaan - waarschijnlijk omdat ze wel vaker [fietsers op de stoep](waarom) ziet - een kwestie van [jaloezie](waarom) en de onzekerheid - ik weet dat ie [niet super lekker in zijn vel zat](waarom) dus misschien komt het daar door - het was gewoon [slechte timing](waarom). - nou ik denk de vorm waarin dat was hoe het gebeurde een [nieuw inzicht](waarom) was - ik denk niet om pijn te doen maar het is ook meer een [zakelijke overweging](waarom) was - ik denk dat ze het gewoon [vergeten](waarom) was eigenlijk - pure [haat](waarom) is het - ik heb [geen idee](waarom) - weet ik veel - dat was [onkunde](waarom) verwacht ik + Hmm, ja. Dat zou kunnen. Wat had deze persoon anders kunnen doen?>her.anders ## intent:anders - volgende keer [beter opletten](anders) - gewoon [niet](anders) tot in den treure [overhalen](wat) - op het moment dat ik zeg niet [dat dat dan genoeg](anders) is. - meerdere dingen ze had even kunnen zeggen dat ik [moest opletten](anders) + En wat was jouw aandeel hierin?>her.rol ## intent:rol - ik laat dan ook [merken](wat) dat ik het [moeilijk vind om weg](rol) te gaan - ik had gewoon gelijk toen het nat was en had [super voorzichtig](rol) kunnen zijn - mijn rol was dat ik haar [in de weg zat](rol) - mijn rol was dat ik uiteindelijk de gene was die het [accepteerde](rol) en verder ging - dat vind ik een [moeilijke vraag](rol) - misschien heb ik niet duidelijk gemaakt dat ik [serieus](rol) was - het ging [over mij](rol) - ik [hoorde het aan](rol) - ik had haar misschien wel [kunnen bellen](rol) nadat we ruzie hebben gehad - ik had iets beter [kunnen doorlopen](rol) natuurlijk - het lag helemaal [niet aan mij](rol) - ik speelde [geen](rol) rol + %Goed, dat waren mijn vragen. Ik denk dat ik genoeg weet om jou te kunnen\ helpen. Ik ga nu aan de slag om het perfecte excuus voor jou te genereren. ## intent:genoeg - stop er maar mee - ik heb er genoeg van - zo is het wel genoeg - ik ben er wel klaar mee + %Goed, dat waren mijn vragen. Ik denk dat ik genoeg weet om jou te kunnen\ helpen. Ik ga nu aan de slag om het perfecte excuus voor jou te genereren. ## intent:herhalen - watte - [nog eens](herhaling) - kun je dat [herhalen](herhaling) - kun je dat [nog eens zeggen](herhaling) - wat zei je - wat zeg je - ik heb het niet goed [verstaan](herhaling) - ik heb het niet helemaal [gevolgd](herhaling), zou je dat kunnen herhalen - zou je dat in [andere woorden](herhaling) uit kunnen leggen - wat was dat [laatste](herhaling) + (me.lastoutput) ## intent:meer-meer - dat iedereen er alles aan doet om [over je grenzen](meer1) heen te gaan - ik vind het lastig om mijn [eigen grenzen](meer2) aan te geven en dat andere mensen die dat weten ook een beetje misbruik van maken - ze had het als het goed is de dag ervoor al [gelakt](wat) en [ik dacht dat het droog was](meer1) - ze zei [je begrijpt er helemaal niets van](meer1) terwijl ik juist wel over haar had nagedacht - ik denk dat het gewoon [heel moeilijk was](meer1) en dat ze [dominanter is](waarom) dan ik - nou eigenlijk was het een [extern bureau](meer1) dat was ingehuurd - eh ja [wat moet ik](meer1) er nog meer over zeggen - uhm - dat soort dingen zorgen voor een [vreemde interactie](meer1) met iemand - dat weet ik [niet](meer1) - ja [begrijp je](meer1) wat ik bedoel - ik had het naar [tessa](wie) geappt - ik zou graag een sorry willen oh ja zo had ik het nog niet bekeken - ja dat heeft me altijd [dwars gezeten](meer2) en toen ik terug kwam heb ik wel eventjes mijn tijd moeten hebben - hij was ineens [verdwenen](meer2) en ja en ik voelde me te [beschaamd](gevoel) - nou en ik had wel gehoopt dat hij er [op was teruggekomen](meer2) - dat hij er [gevolg aan](meer2) zou geven - het was [duidelijk](meer2) dat het zo ging - ik had wel [gehoopt](meer2) dat hij daar op terug zou komen + *uhm, ja. Ga door.>her.meer2 + *uhm, ja. Ga door.>her.meer1 ## intent:byebye + ~bedankt en tot ziens. ## clue:naam p 0 v Moniek t SPEC LID N ## clue:waarvoor p 10 v uitgescholden t N WW ADJ ## clue:meer1 p 20 v wat en zo ## clue:meer2 p 30 v wat en zo ## clue:aangedaan p 40 v pijn t N ADJ WW ## clue:gevoel p 50 v Geschrokken t ADJ N WW ## clue:wie p 60 v Gerard t SPEC LID ADJ N TW ## clue:waarom p 70 v vergeten t N WW ## clue:anders p 65 v mondhouden t WW ADJ ## clue:rol p 80 v opletten t WW ADJ N ## clue:waar p 90 v stoep t N ## clue:wat p 91 v gelakt t N WW ## clue:geslacht p 100 v v ## clue:lastoutput p 100 v uhm ## clue:lastinput p 100 v uhm
Niet alleen het model is anders in de Sorry Automat. Er wordt
bediend met een enkele knop die de start-dialoog inzet. Verder
wordt de microfoon uitgezet bij aanvang om te voorkomen dat
tussen start en voorlezen er een intent wordt opgevangen (daar
wordt dan namelijk gewoon op gereageerd). Ook direct voorafgaand
aan het genereren van het rapport wordt de microfoon
uitgezet. Het wachtmuziekje (nee hoor, er wordt gesproken) dat
wordt afgespeeld is de laatste melding, maar mag niet kort ervoor
door het matchen van een intent worden verziekt. De
excuus-generator (bin/makeanexcuse) zet de microfoon uit. Later
zal bin/tts dat ook doen, maar er zit zeker een seconde tussen
die twee en die kan fataal zijn als er veel gekletst wordt.
3.4.2.4 PIntents
PIntents zijn de teksten die ontvangen kunnen worden, de teksten
die uitgesproken worden door Pinteresque zijn de PIntexts. In
de model-file worden ze, onder de intent-naam, voorafgegaan door een -.
3.4.2.5 PIntexts
De teksten die uitgaan, die dus worden uitgesproken door
Pinteresque, worden op een vergelijkbare manier uitgeschreven. In
de model-file worden ze, onder de intent-naam, voorafgegaan door
een +.
De PIntexts gebruiken een extra semantisch detail: de intent-tekst
van vragen die een of meerdere clues oplossen worden voorzien een
extra > <intent-naam> constructie. Die wordt in de uitgesproken
tekst genegeerd, en fungeert als een manier om aan te geven dat
deze tekst een oplossing voor de genoemde clue provoceert bij de
ander (nl. her).
3.4.2.6 Syntax van de modellen
Voor de modellen-bestanden (.md aka Markdown) gelden wat
regels.
De intents worden voorafgegaan door een pintent-sign:
-
De reacties op intents, de pintexts, worden voorafgegaan door een pintext-sign:
+
De pintexts kunnen zelf voorafgegaan worden door een modifier, zie sectie Het model.
Lange teksten bedoeld voor pintents of pintexts kunnen met een continuation-character van een nieuwe regel worden voorzien. Die nieuwe regel moet dan direct op deze letter volgen.
\
Daar blijft het echter niet bij, er worden meer signs gebruikt voor pintexts. Bijvoorbeeld voor de clues.
[pvt]
Samenhangend met de gebrekkige parsing van de model-bestanden, kunnen in pintexts geen ‘:’-tekens gebruikt worden. Omdat de meeste spraaksoftware niet kan omgaan met de subtiliteiten van de ‘:’, zal dit geen beperking vormen.
Voor ASR en NLU verdient het aanbeveling om interpunctie bij de pintents zoveel mogelijk weg te laten. Bij de pintexts wordt dit juist weer aangemoedigd.
Last–but–not–least; een puntkomma (‘;’) aan het begin van de regel wordt als commentaar gezien, de gehele regel wordt niet gebruikt.
3.4.3 ASR
Vooralsnog gaan we uit van gebruik van de Google speech API. Geen Kaldi, lokaal en met de NL-modellen van de UT dus.
Het commando dat ASR uitvoert heet bin/asr
MICDEVICEOPTION="-D ${MICDEVICE}" [ "$MICDEVICE" = "" ] && MICDEVICEOPTION="" [ "$MICSRATE" = "" ] && MICSRATE="<<audio-samplerate>>" [ "$SPEECHSRATE" = "" ] && SPEECHSRATE="<<audio-samplerate>>" trap "exit 0" 13 set -o pipefail arecord ${MICDEVICEOPTION} -r ${MICSRATE} -c 1 -f <<audio-format>> \ -t <<audio-filetype>> -q - </dev/null | \ while : do set -x date -Ins 1>&2 sox -r ${MICSRATE} -L -e signed -b 16 -c 1 -t raw - \ -r ${MICSRATE} -L -e signed -b 16 -c 1 -t raw - \ contrast 100 \ vad -t 5 -p 0.5 | \ ./livecaption -e LINEAR16 -r ${SPEECHSRATE} [ "$?" = 1 ] && exit $? date -Ins 1>&2 set +x done
De -d60 van arecord neemt 60 seconden audio op en stopt dan,
dat is in lijn met de 60 seconden grens van de Google Streaming
Speech API. Met Kaldi wordt de -d60 weggelaten.
Vanwege de 60 seconden grens van Google wordt er elke minuut, heel
kort, audio gemist. De while :-loop start arecord direct
opnieuw, maar er blijft een kans op het missen van spraak. Zolang
we Google Speech API gebruiken blijft dit een geaccepteerd
probleem.
3.4.3.1 Google
Een on-line alternatief is Google Speech API.
https://github.com/GoogleCloudPlatform/golang-samples/blob/master/speech/livecaption/README.md laat zien hoe je live captured.
met arecord en de juiste parameters stuur je audio naar het
livecaption programma:
arecord -d60 -r 16000 -c 1 -f S16_LE -t raw -q - | ./livecaption -e LINEAR16 -r 16k
livecaption haal je op met:
go get -u cloud.google.com/go/speech/apiv1 en go get livecaption en
go build livecaption. Een en ander is opgenomen in de repository van
Pinteresque.
De Google Streaming Speech API voor ASR kent een limiet van 60
seconden, dat is de reden achter de while :-lus. Gepoogd is om
de livecaption binnen main() te laten lussen, maar dat
resulteert na iets meer dan 60 seconden toch in een fatale
foutmelding.
Met de Asynchrone API kan de 60 seconden grens wel doorbroken worden, maar dan moeten er audio-bestanden richting Google Cloud worden afgeleverd, dat is in onze toepassing niet erg bruikbaar, we willen juist streamen.
3.4.3.1.1 ASR met de Google API
De file die sterk gebaseerd is op het
Google voorbeeld is
p-livecaption.go. De enige wijziging behelst het beperken van
de output tot alleen de tekst van de beste match. In commentaar
een poging om de 60 seconden limit van de Streaming API te
omzeilen, maar het context-object lijkt tegen renewal bestand
te zijn. Ook als na elke regel alles opnieuw wordt gedaan, zal
er na 60 seconden een fout optreden. Zie voor de gebruikte
oplossing het shell-script voor ASR: 20.
package main import ( "context" "fmt" "io" "log" "os" "errors" "strings" "time" "flag" "regexp" speech "cloud.google.com/go/speech/apiv1" speechpb "google.golang.org/genproto/googleapis/cloud/speech/v1" ) func Wordcount(value string) int { re := regexp.MustCompile( `[\S]+` ) results := re.FindAllString( value, -1 ) return len( results ) } func main() { var filename, encodingname, sampleratename string var maxutterancetime, maxutterancecnt, silencewatermark int var verbose bool flag.StringVar( &filename , "f", "", "Name of audio file") flag.StringVar( &encodingname , "e", "LINEAR16", "Name of audio encoding, only LINEAR16 and OGG_OPUS are supported") flag.StringVar( &sampleratename , "r", "16000", "Samplerate of audio, only 8k, 16k, 32k and 48k are supported") flag.IntVar( &maxutterancetime, "T", 60, "(NOT YET IMPLEMENTED) Maximum time to process a single utterance in seconds") flag.IntVar( &maxutterancecnt , "C", 160, "Maximum number of words to process in a single utterance") flag.IntVar( &silencewatermark, "S", 900, "Number of milliseconds of no words considered as silence") flag.BoolVar( &verbose, "v", false, "Add more messaging to stderr") flag.Parse() audioencoding := speechpb.RecognitionConfig_<<google-audio-format>> switch encodingname { // see https://cloud.google.com/speech-to-text/docs/encoding case "LINEAR16": audioencoding = speechpb.RecognitionConfig_LINEAR16 case "OGG_OPUS": audioencoding = speechpb.RecognitionConfig_OGG_OPUS default: log.Fatal( errors.New( "Unsupported audioencoding selected" ) ) } var samplerate int32 samplerate = 16000 switch sampleratename { // see https://cloud.google.com/speech-to-text/docs/encoding case "8k", "8000": samplerate = 8000 case "16k", "16000": samplerate = 16000 case "32k", "32000": samplerate = 32000 case "48k", "48000": samplerate = 48000 default: log.Fatal( errors.New( "Unsupported samplerate selected" ) ) } if verbose { log.Printf( "Capturing audio with encoding %s, sampleing at %d Hz\n", encodingname, samplerate ) } ctx := context.Background() client, err := speech.NewClient(ctx) if err != nil { log.Fatal(err) } stream, err := client.StreamingRecognize(ctx) if err != nil { log.Fatal(err) } if err := stream.Send(&speechpb.StreamingRecognizeRequest{ StreamingRequest: &speechpb.StreamingRecognizeRequest_StreamingConfig{ StreamingConfig: &speechpb.StreamingRecognitionConfig{ Config: &speechpb.RecognitionConfig{ Encoding: audioencoding, SampleRateHertz: samplerate, LanguageCode: "<<lang-tag>>-<<region-tag>>", MaxAlternatives: 1, }, SingleUtterance: false, InterimResults: true, }, }, }); err != nil { log.Fatal(err) } InputFile := os.Stdin if filename != "" { if InputFile, err = os.Open( filename ); err != nil { log.Fatal( err ) } } go func() { buf := make([]byte, 1024) for { n, err := InputFile.Read(buf) if n > 0 { if err := stream.Send(&speechpb.StreamingRecognizeRequest{ StreamingRequest: &speechpb.StreamingRecognizeRequest_AudioContent{ AudioContent: buf[:n], }, }); err != nil { log.Printf("Could not send audio: %v", err) } } if err == io.EOF { if err := stream.CloseSend(); err != nil { log.Fatalf("Could not close stream: %v", err) } return } if err != nil { log.Printf("Could not read from stdin: %v", err) continue } } }() completeNotFinalUtterance := "" printout := time.NewTimer( 59 * time.Second ) for { resp, err := stream.Recv() if err == io.EOF { break } if err != nil { log.Fatalf("Cannot stream results: %v", err) } if err := resp.Error; err != nil { if err.Code == 3 || err.Code == 11 { log.Print("WARNING: Speech recognition request exceeded limit of 60 seconds.") } log.Print("Could not recognize: %v", err) os.Exit( 0 ) } // hm, this is solved in a much better way in TEAM completeNotFinalUtterance = "" for _, result := range resp.Results { for _, alt := range result.Alternatives { if !result.IsFinal { completeNotFinalUtterance = completeNotFinalUtterance + " " + strings.TrimLeft( alt.GetTranscript(), " " ) if verbose { log.Printf( "...: %s", completeNotFinalUtterance ) } //log.Printf( "Stop timer\n" ) if Wordcount( strings.TrimLeft( completeNotFinalUtterance, " " ) ) >= maxutterancecnt { toutter := strings.TrimLeft( completeNotFinalUtterance, " " ) if verbose { log.Printf( "Maxutterancecnt exceeded with result %s\n", toutter ) } _, err := fmt.Printf("%s,\n", toutter ) if err != nil { // probably EOF (end of input) or EPIPE (end of output), don't worry, but fail anyway os.Exit( 1 ) } os.Exit( 0 ) // chickening out, as not exiting makes partial utterances come out double and double, GCP } if !printout.Stop() { <- printout.C } printout = time.AfterFunc( time.Duration( silencewatermark ) * time.Millisecond, func() { toutter := strings.TrimLeft( completeNotFinalUtterance, " " ) if verbose { log.Printf( "Timerevent occured with result %s\n", toutter ) } _, err := fmt.Printf("%s,\n", toutter ) if err != nil { // probably EOF (end of input) or EPIPE (end of output), don't worry, but fail anyway os.Exit( 1 ) } os.Exit( 0 ) // chickening out, as not exiting makes partial utterances come out double and double, GCP }) } else { toutter := strings.TrimLeft( alt.GetTranscript(), " ") if verbose { log.Printf( "Result [%s], final.\n", toutter ) } if toutter != "" { _, err := fmt.Printf("%s\n", toutter ) if err != nil { // probably EOF (end of input) or EPIPE (end of output), don't worry, but fail anyway os.Exit( 1 ) } else { os.Exit( 0 ) // exit for: we did something! } } } break // we only need the top alternative } } } }
The livecaption-program fails on end-of-file and other fatal
errors. Timeouts, finishing an utterance and other
(semi)-successful happenings end in exit(0). This is for the
calling-script to error out only when there is nothing to hear
anymore.
Stopping the output (no reader present) is also a valid
way for stopping this program.
Also note that we're using final as well as partial results from the API. This is for coping with noisy environments and typical (not for Selection Automat and not for Pinteresque) WEB-use of this bot. WEB-use will not indicate any silence for the API for delivering a final result. Hence the result will never come. Using a time-out of 900 milliseconds, we deliver a result to the pipe-line further on anyway.
So where normally an end-of-speech is indicated by a pause in sound of the speaker, we now have an end-of-speech induced by a pause in text received. Note that in the induced case, the sentence ends in a ‘,’.
3.4.4 NLU
We gebruiken Rasa-NLU, maar aangezien daar geen pipeline-ready
oplossing voor is, is er toch een python3-programma nodig om
de teksten op input te vertalen naar intents op output. Gelukkig
is het een simpel programma dat wel met python3 -u gestart moet
worden om buffering te voorkomen.
import sys import os import signal from rasa_nlu.model import Interpreter import json def doNLU( model ): interpreter = Interpreter.load( "<<nlu-model-dir>>/" + model ) line = sys.stdin.readline() while line: if line.startswith( "<<nlu-command-prefix>>" ): # it's a command command = line[ len( "<<nlu-command-prefix>>" ): ].rstrip() if command.startswith( "<<nlu-model-command>> " ): newmodel = command[ len( "<<nlu-model-command>> " ): ] if newmodel != model: model = newmodel interpreter = Interpreter.load( "<<nlu-model-dir>>/" + model ) try: print( command ) # repeat for further down the pipe-line except IOError: # handle output being gone break else: try: result = interpreter.parse( line.rstrip() ) print( json.dumps(result) ) except IOError: # handle output being gone break try: sys.stdout.flush() # try to provoke an IOError in case stdout closed line = sys.stdin.readline() except IOError: # handle input being gone break model = "kappersklant" if len( sys.argv ) == 2: model = sys.argv[ 1 ] if not os.path.isdir( "<<nlu-model-dir>>/" + model ): print( "Given parameter is not a model: ", model ) sys.exit( -1 ) doNLU( model )
Iets minder simpel wordt het doordat dit programma ook in staat is om commando's te verwerken. Zo kan het programma dat input levert voor NLU, het model wijzigen. Mogelijk komen er later nog andere wijzigingen.
Ook een complicatie is dat mogelijkerwijs de output stopt
(pinteresque stopt), maar dat de nlu-pipe dat niet merkt. De
Unix EPIPE error die dat oplevert komt pas met de readline()
binnen.
Merk op dat de ingelezen regel een newline aan het einde bevat,
die wordt er met rstrip() afgehaald voordat de tekst naar de
Rasa-interpreter gestuurd wordt.▮
Voor de commando-prefix wordt gebruikt:
#!
En het wisselen van model gebeurt met:
model
Een gesprek eindigt met:
end
Binnen de NLU-pipe is de directory van belang waar de modellen onder zitten:
models
3.4.4.1 NLU/Rasa
De inhoud van de configuratie staat opgesomd in figuur 26.
language: <<lang-tag>> pipeline: spacy_sklearn
spacy_sklearn staat voor een collectie van componenten. Met
betrekking tot de pipeline moet nog veel geleerd worden. Zie
daarvoor ook de
discussie
op stackoverflow.
De intents zelf worden hieronder besproken en staan genoemd in het
bestand pintents.md. Het formaat staat min of meer omschreven in
NLU Dataformat,
helaas is dat geen formele omschrijving.
Het command voor NLU is bin/nlu en roept bovenstaand
python-script aan met de -u-optie voor unbuffered IO.
Dat niet-bufferen is nodig omdat
beide processen binnenkomende regels opsparen, de orchestrator
moet ze direct ontvangen om terug te kunnen spreken.
model=kappersklant [ "$1" != "" ] && model="$1" [ ! -r "models/${model}/training_data.json" ] && \ echo "No models found in models/${model}/" [ ! -r "models/${model}/training_data.json" ] && \ exit 1 python3 -u ./nlu-pipe.py "${model}"
3.4.5 Annotate
Frog analyseert de tekst en annoteert elk woord met betrekking tot de grammaticale rol ervan in de zin.
cat -u
Omdat Frog nu nog als dienst gebruikt wordt vanuit de
Orchestrator, is het script leeg. De JSON die uit bin/nlu komt
zou ook door het annotator-script kunnen worden voorzien van extra
attributen met daarin de informatie van Frog. Dan is een filter
fraaier en kan het gebruik in de orchestrator verdwijnen.
Aan Frog kan ook nog het matchen op woordenlijsten toegevoegd worden, dit om sprekers-perspectief, positief/negatief en mogelijk andere sentimenten toe te voegen.
3.4.6 Applicatie
Pinteresque, de orchestrator, leest JSON-geformatteerde intents van de input. Op de output verschijnt de tekst die bedoeld is voor de persoon die de input maakte.
Het geschetste scenario in figuur 2 past precies op de GO-code voor het package main. In het scenario worden laag bij de grondse zaken als database toegang en alle foutafhandeling niet getoond, dat voegt de code dan nog toe.
package main <<imports-for-orchestrator>> // while receiving nothing from NLU, we break the silence after some time const AcceptableSilence = <<acceptable-silence>> var SilenceBreaker = rasa.IntentContainer{ Intent: rasa.Intent{ Name: "none", Confidence: 1.0, }, Text: "silencebreaker", } var accepting = false var options struct { NoSilencebreaker bool `short:"b" description:"Silence will not be interrupted by a new question"` Model string `short:"m" description:"Model to start with" default:"kappersklant" env:"MODEL"` Startself bool `short:"s" description:"Start the model without waiting for a command"` Verbose bool `short:"v" description:"Add some messaging to stderr" env:"VERBOSE"` } func main() { _, err := flg.Parse( &options ) if err != nil { log.Printf( "(pinteresque) Error parsing options: %v", err ) os.Exit( 1 ) } model := options.Model log.Printf( "Starting model %s\n", model ) doSbrkr := !options.NoSilencebreaker startself := options.Startself accepting = options.Startself if startself { log.Printf( " accepting, starting self\n" ) } else { log.Printf( "Not accepting,Not starting self\n" ) } db := pg.Connect( &pg.Options{ <<pgdb-connect-params>> } ) defer db.Close() frog := newFrog() if frog != nil { defer frog.Connection.Close() } dontunderstandUtterance := getStandardUtterances( db, model ) persona, person, gender := makePersonAndPersona( db, model ) prevgender := gender defer persons.EndAPerson( db, persona ) defer persons.EndAPerson( db, person ) if model == "sorry" { if prevgender == "" { prevgender = "v" log.Printf( "Weird, prevgender is empty, defaulting to v" ) } } var clueFindingText texts.Texts // when input comes in, we need to know var textUsed texts.Texts // on what text, we keep it in these two if startself { textUsed = doFirstOutput( db, model, persona, person, gender ) clueFindingText = textUsed } else { log.Printf( "Not starting self\n" ) } var silenceBreaker *time.Timer // this is where the timer sits if doSbrkr { <<start-silence-breaker>> } for true { // in this loop, calls cannot fail, keep listening and talking gender = prevgender log.Printf( "reading stdin\n" ) theline, err := readLine() log.Printf( "done reading stdin [%s]\n", theline ) if err != nil && err == io.EOF { // well, except if input stops, we bail out persons.EndAPerson( db, persona ) persons.EndAPerson( db, person ) break } if doSbrkr { <<reset-silence-breaker>> } var theIntent rasa.IntentContainer if err := unMarshallJson( []byte( theline ), &theIntent ); err != nil { // we may receive pinteresque commands from NLU as non-json text. words := strings.Split( strings.TrimRight( theline, "\n" ), " " ) if len( words ) < 1 { fmt.Fprintf( os.Stderr, "error understanding json (receiving %v) on Stdin: %v", words, err ) continue } switch words[ 0 ] { case "<<nlu-model-command>>": log.Printf( "Restarting for model [%s]\n", words[ 1 ] ) model = words[ 1 ] persons.EndAPerson( db, persona ) persons.EndAPerson( db, person ) dontunderstandUtterance = getStandardUtterances( db, model ) persona, person, gender = makePersonAndPersona( db, model ) defer persons.EndAPerson( db, persona ) defer persons.EndAPerson( db, person ) if model == "sorry" { texts.Output( gender, "tput clear" ) } textUsed = doFirstOutput( db, model, persona, person, gender ) clueFindingText = textUsed if doSbrkr { <<reset-silence-breaker>> } accepting = true case "<<nlu-end-command>>": log.Printf( "Ending conversation with id: %d\n", person.Id ) textUsed = doByeByeOutput( db, model, persona, person, gender ) clueFindingText = textUsed persons.EndAPerson( db, persona ) persons.EndAPerson( db, person ) if doSbrkr { _ = silenceBreaker.Stop() } accepting = false default: fmt.Fprintln( os.Stderr, "error understanding pin-command on Stdin: [%v]", words ) } continue // it makes no sense to process the intent, it is not there! } if !accepting { log.Printf( "Continuing because of not accepting, skipping %v", theIntent ) continue } clues.UpdateIfExists( db, persona.Id, persona.Model, "lastinput", theIntent.Text ) // make (me.lastinput) available sents, err := frog.Analyse( theIntent.Text ) // analyse one single sentence if err != nil { log.Printf( "Analysing text [%s] using frog failed [%v]\n", theIntent.Text, err ) } else { log.Printf( "Frog says [%v]\n", sents[ 0 ] ) if len( sents ) > 1 { log.Printf( "Frog returned more than one line! Weird\n" ) } } intentAnalysis := sents[ 0 ] // use result for the first (and hopefully only) sentence var cluesSolvedCount int intentname := "" cluename := "" if cluesSolvedCount, cluename, intentname, err = clues.FindSaveCluesFromIntent( db, person.Id, person.Model, theIntent, intentAnalysis ); err != nil { log.Printf( "FindSaveCluesFromIntent (db, %v, %v) failed [%v]\n", person, theIntent, err ) } else { log.Printf( "Saved %d clues from intent, clue[%s] intent[%s], cluetoinduce: [%v or %v]\n", cluesSolvedCount, cluename, theIntent.Intent.Name, clueFindingText.Cluetoinduce, textUsed.Cluetoinduce ) theIntent.Intent.Name = intentname } // if solved is 0; try harder in case there is an induced clue. // we may even have induced two clues: // one from the textUsed and one from clueFindingText // try both (if not similar) and if Cluetoinduce != "" if cluesSolvedCount == 0 { // accept answer is for this clue, try harder if clueFindingText.Cluetoinduce != "" { if count, cname, intentname, err := clues.SaveClueFromIntent( db, person.Id, person.Model, theIntent.Text, theIntent.Intent.Name,intentAnalysis, clueFindingText.Cluetoinduce ); err != nil { log.Printf( "Knowing clue (%s), erroring out on SaveClueFromIntent with: %v\n", clueFindingText.Cluetoinduce, err ) } else { cluesSolvedCount += count theIntent.Intent.Name = intentname cluename = cname } } if textUsed.Cluetoinduce != "" && textUsed.Cluetoinduce != clueFindingText.Cluetoinduce { if count, cname, intentname, err := clues.SaveClueFromIntent( db, person.Id, person.Model, theIntent.Text, theIntent.Intent.Name, intentAnalysis, textUsed.Cluetoinduce ); err != nil { log.Printf( "Knowing clue (%s), erroring out on SaveClueFromIntent with: %v\n", textUsed.Cluetoinduce, err ) } else { cluesSolvedCount += count if textUsed.Cluetoinduce == "her.naam" || textUsed.Cluetoinduce == "naam" { // special case, should generalize theIntent.Intent.Name = "naam" } else { theIntent.Intent.Name = intentname cluename = cname } } } if cluesSolvedCount == 0 { log.Printf( "Knowing the clue (%s or %s or %s), still could not get it from from intent [%v]\n", clueFindingText.Cluetoinduce, textUsed.Cluetoinduce, cluename, theIntent.Text ) } } intentIsQuestion, err := intentAnalysis.IsQuestion() if err != nil && intentIsQuestion && cluesSolvedCount > 0 { log.Printf( "Solved clues from a question, weird [%s]\n", theIntent.Text ) } // now find words to speak, possibly using clues just discovered firstOutput := "" textUsed, firstOutput = findSuitableText( db, model, theIntent, persona, person, cluename, theline, "", dontunderstandUtterance ) if model == "sorry" && textUsed.Modifier == "<<to-finish-with>>" { // we're done talking, maybe generate a report and go back to wait for next call log.Printf( "In model sorry, finish-text uttered, not accepting any incoming speech (text) until introduction" ) log.Printf( "Some report with (person,persona) tuple: (%d,%d)", person.Id, persona.Id ) p := strconv.Itoa( person.Id ) pa := strconv.Itoa( persona.Id ) //persons.EndAPerson( db, persona ) //persons.EndAPerson( db, person ) cmd := exec.Command( "bin/makeanexcuse", p, pa ) if err := cmd.Run(); err != nil { // maybe use Start and pick Wait in a go-routine log.Printf( "(sorry) makeanexcuse failed [%v]\n", err ) } accepting = false texts.Output( prevgender, firstOutput ) log.Printf( "Session ended; continuing because of not accepting" ) continue } log.Printf( "Text to utter has modifier: %s", textUsed.Modifier ) texts.Output( prevgender, firstOutput ) if !accepting { log.Printf( "should not occur: Continuing because of not accepting" ) continue } secondOutput := "" if !textUsed.IsQuestion() && cluesSolvedCount < 1 { // i.e. we havent solved clues yet, press for more clue-solving! // but dont bother if we asked a question in the first part of our text. // it is not nice to ask two questions in one turn. clueFindingText, secondOutput = findSuitableClueInducer( db, model, theIntent, persona, person, firstOutput, theline) } if model == "sorry" && textUsed.Modifier == "<<to-finish-with>>" { log.Printf( "In model sorry and received clue-inducing finish-text, weird" ) } texts.Output( prevgender, secondOutput ) clues.UpdateIfExists( db, persona.Id, persona.Model, "lastoutput", firstOutput + " " + secondOutput ) log.Println( "" ) } } func doFirstOutput( db *pg.DB, model string, persona persons.Persons, person persons.Persons, personagender string ) ( texts.Texts ) { if first, err := texts.StartText( db, model ); err == nil { output := first.ReduceText( db, persona.Id, person.Id, person.Model ) log.Printf( "Uttering first [%s]", output ) texts.Output( personagender, output ) clues.UpdateIfExists( db, persona.Id, persona.Model, "lastoutput", output ) trail.AddToTrail( db, persona.Id, person.Id, first.Id, "", "", output ) return first } else { return texts.Texts{} } } func doByeByeOutput( db *pg.DB, model string, persona persons.Persons, person persons.Persons, personagender string ) ( texts.Texts ) { if first, err := texts.GoingAwayText( db, model ); err == nil { output := first.ReduceText( db, persona.Id, person.Id, person.Model ) log.Printf( "Uttering byebye [%s]", output ) texts.Output( personagender, output ) clues.UpdateIfExists( db, persona.Id, persona.Model, "lastoutput", output ) trail.AddToTrail( db, persona.Id, person.Id, first.Id, "", "", output ) return first } else { return texts.Texts{} } } func unMarshallJson( theline []byte, theIntent *rasa.IntentContainer ) (err error) { if err = json.Unmarshal( []byte( theline ), &theIntent ); err != nil { return err } theIntent.Text = strings.TrimRight( theIntent.Text, "\n" ) if theIntent.Text == "" { log.Println( "Error unmarhsallJson; empty input" ) return errors.New( "JSON-format error: Empty input encountered" ) } log.Printf( "Going in with intent [%v] with slots [%v] for text [%s]\n", theIntent.Intent, theIntent.Entities, theIntent.Text ) return nil } func findSuitableClueInducer( db *pg.DB, model string, theIntent rasa.IntentContainer, persona persons.Persons, person persons.Persons, firstOutput string, theline string ) ( texts.Texts, string ) { var clueFindingText texts.Texts secondOutput := "" clue, err := clues.TopClue( db, person.Id, model ) if err != nil { log.Printf( "Error getting TopClue: %v?\n", err ) return clueFindingText, "" } else if err == nil && len( clue.Name ) > 0 { if clueFindingText, err = texts.TextForSolvingClue( db, clue.Name, model ); err == nil { if textToAdd := clueFindingText.ReduceText( db, persona.Id, person.Id, person.Model ); textToAdd != firstOutput { log.Printf( "Adding TextForClue: %v?\n", clueFindingText ) secondOutput += " " + textToAdd trail.AddToTrail( db, persona.Id, person.Id, clueFindingText.Id, theIntent.Intent.Name, theline, secondOutput ) } } } return clueFindingText, secondOutput } func findSuitableText( db *pg.DB, model string, theIntent rasa.IntentContainer, persona persons.Persons, person persons.Persons, clue string, theline string, demand string, dontunderstandUtterance texts.Texts ) ( texts.Texts, string ) { var textUsed texts.Texts firstOutput := "" if mytexts, err := texts.TopTexts( db, model, theIntent.Intent.Name, persona.Id, person.Id, clue ); err != nil { log.Printf( "TopTexts failed [%v]", err ) firstOutput = "" } else { log.Printf( "Toptexts returned %d texts\n", len( mytexts ) ) for _, thetext := range mytexts { log.Printf( "Toptexts returned [%v]\n", thetext ) } textUsed = dontunderstandUtterance firstOutput = textUsed.Content for _, thetext := range mytexts { //log.Printf( "Considering a text from TopTexts: [%v], demanding [%s]\n", // thetext, demand ) if demand == "?" { if !thetext.IsQuestion() { continue } } else if demand == "!" { if thetext.IsQuestion() { continue } } firstOutput = thetext.ReduceText( db, persona.Id, person.Id, person.Model ) textUsed = thetext if !texts.HasClueRefs( firstOutput ) { log.Printf( "Using from TopTexts: [%v] as [%s]\n", thetext, firstOutput ) break } } if texts.HasClueRefs( firstOutput ) { // maybe give this particular clue higher priority log.Printf( "No Text left without cleurefs. Skipping [%v]\n", textUsed ) } } trail.AddToTrail( db, persona.Id, person.Id, textUsed.Id, theIntent.Intent.Name, theline, firstOutput ) return textUsed, firstOutput } func personsGender( db *pg.DB, persona persons.Persons ) string { genderClue, err := clues.Clue( db, persona.Id, persona.Model, "geslacht" ) if err != nil { panic( err ) } return genderClue.Value } func newFrog() *frog.FrogClient { connectstring := os.Getenv( "FROG_CONNECT" ) if connectstring == "" { connectstring = "<<frog-connect-params>>" } log.Printf( "Connecting to Frog service at [%s]\n", connectstring ) if frog, err := frog.NewFrogClient( connectstring ); err != nil { log.Printf( "Error %v connecting to Frog service\n", err ) return nil } else { return frog } } func readLine() (string, error) { var result []byte terminator := byte( 0xa ) buf := make( []byte, 1 ) for buf[ 0 ] != terminator { if _, err := os.Stdin.Read( buf ); err != nil { return "", err } result = append( result, buf[ 0 ] ) } return string( result ), nil } func getStandardUtterances( db *pg.DB, model string ) texts.Texts { if dontunderstandUtterance, err := texts.GetText( db, "sorry, ik begrijp je niet", model ); err != nil { panic( err ) } else { return dontunderstandUtterance } } <<define-make-persona-and-person>>
func makePersonAndPersona( db *pg.DB, model string ) (persons.Persons, persons.Persons, string ) { persona := persons.GetAnyPersona( db, model ) person := persons.MakeANewPerson( db, model ) persons.InitCluesForPerson( db, person, model ) log.Printf( "Persona %d and person %d talking with model %s", persona.Id, person.Id, model ) return persona, person, personsGender( db, persona ) }
Pinteresque is gebruiker van de lokale Frog-service. Die is bereikbaar op:
178.79.165.162:8080
Pinteresque is ook gebruiker van de lokale PostgreSQL database-service. De parameters daarvoor zijn:
User: "pin", Password: "ok now", Database: "pin", Addr: "localhost:5432",
Omdat langdurige stiltes mogelijk alleen door de persona onderbroken kunnen worden, wordt er een timer gestart die, als die afloopt, een vraag stelt. In figuur 30 wordt de timer gemaakt en de functie gestart die op die timer wacht. Ofschoon die timer altijd loopt, wordt deze telkens ge-reset als er input komt. Dan is er nl. geen sprake meer van stilte. In figuur 31 wordt de timer gestopt en ge-reset. Er wordt gebruik gemaakt van de acceptable silence constante uit het Rasa-package. 20 seconden klinkt als een redelijke waarde.
silenceBreaker = time.NewTimer( AcceptableSilence ) go func() { for { _, ok := <- silenceBreaker.C if !ok { return } if !accepting { return } _, firstOutput := findSuitableText( db, model, SilenceBreaker, persona, person, "noclue", "", "?", dontunderstandUtterance ) log.Printf( "Issueing output from silenceBreaker: %s\n", firstOutput ) // text must be a question fmt.Printf( gender + " " + firstOutput ) fmt.Printf( "\n" ) } }()
if !silenceBreaker.Stop() { numevents := len( silenceBreaker.C ) if numevents > 0 { if numevents == 1 { <- silenceBreaker.C } else { log.Printf( "Strange: silenceBreaker has several (%d) events queued", numevents ) } } } _ = silenceBreaker.Reset( AcceptableSilence )
import ( "fmt" "log" "os" "os/exec" "time" "io" "strings" "strconv" "errors" "encoding/json" "github.com/go-pg/pg" "gitlab.com/jhelberg/rasa" "pinteresque/persons" "pinteresque/clues" "pinteresque/texts" "pinteresque/trail" "gitlab.com/jhelberg/frog" flg "github.com/jessevdk/go-flags" )
3.4.6.1 Rasa op input
De binnenkomende JSON bevat een intent met name, een string en
confidence, een float.
Dan volgt een array van entities aka slots. Daarna de
intent-ranking. Die ranking is interessant, maar alleen nuttig
als de intent niet voldoet. Wel interessant is de text, dat is
een copie van de binnengekomen tekst.
De GO-types daarvoor staan hieronder min of meer één-op-één gedeclareerd in het package rasa (import "gitlab.com/jhelberg/rasa").
3.4.6.2 Gebruik van Frog
Er wordt gebruik gemaakt van het go package
"gitlab.com/jhelberg/frog" voor de interface naar de Frog-server.
Pinteresque gebruikt de zgn. PoS TAG zoals gedocumenteerd in
POS Manual.
Hieronder een korte uitleg (1-op-1 gecopieerd uit de
POS Manual) van de gebruikte tagging. De string die Pinteresque
terugkrijgt van Frog begint met het soort woord met daarachter,
tussen haakjes, de toevoegingen. Zo levert het woord ‘knip’ uit
de zin “hoe wil je dat ik je knip?” het volgende op:
WW(pv,tgw,ev). En ‘halflang’ in de zin “ok, halflang haar en
oren bedekt dus”: ADJ(prenom,basis,zonder).
Voor bijwoorden wordt ‘BW’ gebruikt en voor tussenvoegsel: ‘TSW’. Daarvoor gelden geen toevoegingen of verdere classificaties.
De ‘N’ staat voor noun ofwel zelfstandig naamwoord:
| Zelfst. naamwoord | Toevoegingen | Voorbeeld |
|---|---|---|
| N | soort,ev,basis,zijd,stan | stoel |
| N | soort,ev,basis,onz,stan | kind |
| N | soort,ev,dim,onz,stan | stoeltje |
| N | soort,ev,basis,gen | ’s avonds |
| N | soort,ev,dim,gen | vadertjes pijp |
| N | soort,ev,basis,dat | ter plaatse |
| N | soort,mv,basis | stoelen |
| N | soort,mv,dim | stoeltjes |
| N | eigen,ev,basis,zijd,stan | Noordzee |
| N | eigen,ev,basis,onz,stan | het Nederlands |
| N | eigen,ev,dim,onz,stan | Kareltje |
| N | eigen,ev,basis,gen | des Heren |
| N | eigen,ev,dim,gen | Kareltjes fiets |
| N | eigen,ev,basis,dat | wat den Here toekomt |
| N | eigen,mv,basis | Ardennen |
| N | eigen,mv,dim | de Maatjes |
| N | soort,ev,basis,genus,stan | een riool |
| N | eigen,ev,basis,genus,stan | Linux |
Bijvoeglijke naamwoorden (aka adjectives) worden aangegeven met ‘ADJ’:
| Bijvoeglijk naamwoord | Toevoegingen | Voorbeeld |
|---|---|---|
| ADJ | prenom,basis,zonder | een mooi huis |
| ADJ | prenom,basis,met-e,stan | mooie huizen |
| ADJ | prenom,bassi,met-e,bijz | zaliger gedachtenis |
| ADJ | prenom,comp,zonder | een mooier huis |
| ADJ | prenom,comp,met-e,stan | mooiere huizen |
| ADJ | prenom,comp,met-e,bijz | van beteren huize |
| ADJ | prenom,sup,zonder | een alleraardigst mens |
| ADJ | prenom,sup,met-e,stan | de mooiste keuken |
| ADJ | prenom,sup,met-e,bijz | bester kwaliteit |
| ADJ | nom,basis,zonder,zonder-n | in het groot |
| ADJ | nom,basis,zonder,mv-n | het leuke |
| ADJ | nom,basis,met-e,zonder-n,bijz | hosanna in den hogen |
| ADJ | nom,basis,met-e,mv-n | de rijken |
| ADJ | nom,comp,zonder,zonder-n | |
| ADJ | nom,comp,met-e,zonder-n,stan | een betere |
| ADJ | nom,comp,met-e,zonder-n,bijz | |
| ADJ | nom,comp,met-e,mv-n | de ouderen |
| ADJ | nom,sup,zonder,zonder-n | op z’n best |
| ADJ | nom,sup,met-e,zonder-n,stan | het leukste |
| ADJ | nom,sup,met-e,zonder-n,bijz | des Allerhoogsten |
| ADJ | nom,sup,met-e,mv-n | de slimsten |
| ADJ | postnom,basis,zonder | rivieren bevaarbaar in de winter |
| ADJ | postnom,basis,met-s | iets moois |
| ADJ | postnom,comp,zonder | een getal groter dan drie |
| ADJ | postnom,comp,met-s | iets gekkers |
| ADJ | vrij,basis,zonder | die stok is lang |
| ADJ | vrij,comp,zonder | die stok is langer |
| ADJ | vrij,sup,zonder | die stok is het langst |
| ADJ | vrij,dim,zonder | het is hier stilletjes |
Werkwoorden zijn dan met ‘WW’ aangegeven:
| Werkwoord | Voorbeeld | |
|---|---|---|
| WW | pv,tgw,ev | speel |
| WW | pv,tgw,mv | spelen |
| WW | pv,tgw,met-t | speelt |
| WW | pv,verl,ev | speelde |
| WW | pv,verl,mv | speelden |
| WW | pv,verl-met-t | kwaamt |
| WW | pv,conj,ev | leve de koning |
| WW | inf,prenom,zonder | de nog te lezen post |
| WW | inf,prenom,met-e | een niet te weerstane verleiding |
| WW | inf,nom,zonder,zonder-n | het spelen |
| WW | inf,vrij,zonder | hij zal komen |
| WW | vd,prenom,zonder | een verwittigd man |
| WW | vd,nom,met-e,zonder-n | het geschrevene |
| WW | vd,nom,met-e,mv-n | de gedupeerden |
| WW | vd,vrij,zonder | is gekomen |
| WW | od,prenom,zonder | een slapend kind |
| WW | od,prenom,met-e | een spelende aap |
| WW | od,nom,met-e,zonder-n | het resterende |
| WW | od,nom,met-e,mv-n | de wachtenden |
| WW | od,vrij,zonder | hij liep lachend weg |
Telwoorden, ‘TW’, zijn belangrijk om te herkennen in Pinteresque:
| Telwoord | Voorbeeld | |
|---|---|---|
| TW | hoofd,prenom,stan | vier cijfers |
| TW | hoofd,prenom,bijz | eens geestes zijn |
| TW | hoofd,nom,zonder-n,basis | er is er een ontsnapt |
| TW | hoofd,nom,mv-n,basis | met z’n vieren |
| TW | hoofd,nom,zonder-n,dim | er is er eentje ontsnapt |
| TW | hoofd,nom,mv-n,dim | met z’n tweetjes |
| TW | hoofd,vrij | pagina vijf |
| TW | rang,prenom,stan | de vierde man |
| TW | rang,prenom,bijz | te elfder ure |
| TW | rang,nom,zonder-n | het eerste |
| TW | rang,nom,mv-n | de eersten |
Minder belangrijk lijken de lidwoorden (‘LID’):
| Lidwoord | Voorbeeld | |
|---|---|---|
| LID | bep,stan,evon | het kind |
| LID | bep,stan,rest | de hond(en) |
| LID | bep,gen,evmo | des duivels |
| LID | bep,gen,rest3 | der Nederlandse taal |
| LID | bep,dat,evmo | op den duur |
| LID | bep,dat,evf | in der minne |
| LID | bep,dat,mv | die in den hemelen zijt |
| LID | onbep,stan,agr | een kind |
| LID | onbep,gen,evf | de kracht ener vrouw |
En de voorzetsels (‘VZ’):
| Voorzetsel | Voorbeeld | |
|---|---|---|
| VZ | init | met een lepeltje |
| VZ | fin | liep de trap af |
| VZ | versm | ten strijde |
Ook voegwoorden (‘VG’) lijken niet erg zinnig om te kennen binnen Pinteresque:
| Voegwoord | Voorbeeld | |
|---|---|---|
| VG | neven | Jan en Peter |
| VG | onder | ze komt niet, omdat ze ziek is |
Van de voornaamwoorden (pronouns), ‘VNW’, zijn er talloze (184) die weggelaten worden in dit document.
3.4.6.3 Personas en personen
Bij het instantieren van een persoon (persona of persoon –de gesprekspartner–) worden alle bekende clues ook geinstantieerd. Een persoon kan niet bestaan zonder die clues, je zou kunnen zeggen dat een persoon gedefinieerd wordt door zijn of haar clues. Mogelijk zijn er enkele niet ingevuld; het is aan Pinteresque om ze in te vullen.
package persons import ( "log" "github.com/go-pg/pg" ) type Persons struct { Id int Starttime pg.NullTime Endtime pg.NullTime Isrobot bool Model string } func GetAnyPersona( db *pg.DB, model string ) ( Persons ) { var person Persons _, err := db.QueryOne( &person, ` <<get-any-persona:model>> `, model ) if err != nil { log.Printf( "GetAnyPersona failed [%v], did you load the right model [%s]?", err, model ) panic( err ) } return person } func StartAPersona( db *pg.DB, person Persons ) ( Persons, error ) { _, err := db.QueryOne( &person, ` <<start-persona:person>> `, person.Id ) if err == nil { _, err = db.QueryOne( &person, ` <<get-a-specific-person:person>> `, person.Id ) } return person, err } func EndAPerson( db *pg.DB, person Persons ) error { _, err := db.QueryOne( &person, ` <<end-person:person>> `, person.Id ) return err } func MakeANewPerson( db *pg.DB, model string ) ( Persons ) { var person Persons person.Model = model _, err := db.QueryOne( &person, ` <<make-a-new-person:model>> `, model ) if err != nil { log.Printf( "MakeANewPerson failed [%v]", err ) panic( err ) } return person } func InitCluesForPerson( db *pg.DB, person Persons, model string ) { _, err := db.Query( &person, ` <<initialise-clues-for-person:theperson,model>> `, person.Id, model, model ) if err != nil { panic( err ) } return } func RunningPerson( db *pg.DB ) ( Persons, error ) { var person Persons _, err := db.QueryOne( &person, ` <<current-person>> `) return person, err } func RunningPersona( db *pg.DB ) ( Persons, error ) { var person Persons _, err := db.QueryOne( &person, ` <<current-persona>> `) return person, err } func SetGender( db *pg.DB, person Persons, name string ) ( error ) { var gender string type parm struct { Person int Name string } actual := parm{ Person: person.Id, Name: name} _, err := db.QueryOne( &gender, ` <<update-gender:person,name>> `, actual ) if err != nil && err == pg.ErrNoRows { return nil } return err }
3.4.6.4 Clues
Een clue is niet veel meer dan een persistente eigenschap van een persoon. Er zijn ook clues die niet aan een persoon hangen, die zijn te zien als een lijst van de te gebruiken clues voor een nieuwe of bestaande persoon.
Een persona zal bij aanvang al ingevulde clues hebben, maar indien er een onpersoonlijke clue bijkomt, dan zal Pinteresque die bij instantieren van de persona toevoegen. Weliswaar als niet ingevuld, maar dat is dan tijdelijk.
package clues import ( "os" "fmt" "log" "strings" "strconv" "regexp" "github.com/go-pg/pg" "gitlab.com/jhelberg/rasa" "gitlab.com/jhelberg/frog" ) type Clues struct { Id int Person int Name string Value string Priority int Pit pg.NullTime Model string Postags string } func Clue( db *pg.DB, personId int, model string, name string ) ( Clues, error ) { var clue Clues _, err := db.QueryOne( &clue, ` <<clue:person,name,model>> `, personId, name, model ) if err == pg.ErrNoRows { clue.Name = "" return clue, nil } return clue, err } func TopClue( db *pg.DB, personId int, model string ) ( Clues, error ) { var clue Clues _, err := db.QueryOne( &clue, ` <<top-clue:person,model>> `, personId, model ) if err == pg.ErrNoRows { clue.Name = "" return clue, nil } return clue, err } func (clue *Clues) Save( db *pg.DB ) ( error ) { _, err := db.QueryOne( &clue, ` <<save-a-clue:value,id>> `, clue.Value, clue.Id ) return err } func UpdateIfExists( db *pg.DB, personId int, model string, name string, value string ) { log.Printf( "Saving [%s].\n", name ) if theClue, err := Clue( db, personId, model, name ); err != nil { log.Printf( "No [%s] clue found, not able to update with [%s].\n", name, value ) } else { theClue.Value = value theClue.Save( db ) log.Printf( "[%s] clue saved.\n", name ) } } func findRequiredPostags( db *pg.DB, personId int, name string ) []string { reqs := "" _, err := db.QueryOne( &reqs, ` select coalesce( postags, '' ) from clues where person = ? and name = ? `, personId, name ) if err != nil { return []string{} } return strings.Split( reqs, " " ) } func SaveAClue( db *pg.DB, value string, name string, personId int, model string ) ( error ) { var clue Clues type parm struct { Value string Name string Person int Model string } actual := parm{ Value: value, Name: name, Person: personId, Model: model } _, err := db.QueryOne( &clue, ` <<save-a-clue:value,name,person,model>> `, actual ) return err } func FindSaveCluesFromIntent( db *pg.DB, personId int, personModel string, intent rasa.IntentContainer, analysed frog.Sentence, ) (count int, clue string, iname string, err error) { count = 0 nameSlotDone := false iname = intent.Intent.Name for _, slot := range intent.Entities { if slot.Value == "\n" { // slot.Entity is the name (e.g. naam), slot.Value is it's value (e.g. Joost) continue } // the clue may contain several words. We strip the ones not necessary // The abstract clue (the persona one) has an empty Postags // (anything goes) or contains blank seperated POSTags // one of these Postags must match the tok.POSTag to include // this as an word in the clue slot.Value = stripNonValidWords( db, personId, slot, analysed ) if err = SaveAClue( db, slot.Value, slot.Entity, personId, personModel ); err != nil { if err == pg.ErrNoRows { log.Printf( "Did not save clue: (%s,%s) for person %d, is it missing or double?\n", slot.Entity, slot.Value, personId ) err = nil } else { return count, slot.Entity, iname, err } } count += 1 if strings.HasSuffix( intent.Intent.Name, "naam" ) { nameSlotDone = true } log.Printf( "Slots found in intent [%v] for [%d], count is [%d]\n", slot, personId, count ) } if count == 0 { log.Printf( "No slots found in intent [%s] for [%d], count is [%d]\n", intent.Intent.Name, personId, count ) } oneWord, err := regexp.MatchString( "^\\w+$", intent.Text ) if err != nil { return count, "", iname, err } conf := intent.Intent.Confidence cluesolved := "" switch { case !nameSlotDone && conf > 0.3 && strings.HasSuffix( intent.Intent.Name, "naam" ): log.Printf( "Trying naam-clue [%s] for [%d], count is [%d]\n", intent.Text, personId, count ) words := strings.Split( intent.Text, " " ) verbskipped := false for _, word := range words { tok := analysed[ word ] if !verbskipped && tok.IsVerb() { log.Printf( "[%s] is a verb, skipping as name\n", tok.Token ) verbskipped = true // allow skipping once, after that it may be a name after all continue } if tok.IsGreeting( analysed ) { log.Printf( "[%s] is a greeting, skipping as name\n", tok.Token ) continue } if ct, err := tryNameClue( db, word, personId, personModel ); err != nil { return count, "", iname, err } else { count += ct iname = "naam" cluesolved = "naam" } } case oneWord && strings.Contains( intent.Intent.Name, "leeftijd" ): log.Printf( "Trying one-word-leeftijd-clue %s for %d, count is %d\n", intent.Text, personId, count ) tok := analysed[ intent.Text ] if len( analysed ) == 0 || tok.IsNumber() { log.Printf( "Possible number found: [%s]\n", intent.Text ) if ct, err := tryAgeClue( db, intent.Text, personId, personModel ); err != nil { return count, "", iname, err } else { count += ct iname = "leeftijd" cluesolved = "leeftijd" } } case oneWord: // can be yes, no or sorry log.Printf( "Trying one-word-clue [%s] for [%d], count is [%d]\n", intent.Text, personId, count ) if ct, err := tryNameClue( db, intent.Text, personId, personModel ); err != nil { return count, "", iname, err } else { count += ct iname = "naam" // we did solve a name, this must be a naam intent cluesolved = "naam" } default: log.Printf( "Giving up on further clue-solving %s for %d, count is %d\n", intent.Text, personId, count ) } return count, cluesolved, iname, nil } var reduceCluetoinduce = regexp.MustCompile( "her\\." ) func SaveClueFromIntent( db *pg.DB, personId int, personModel string, intentText string, intentName string, analysed frog.Sentence, clueText string, ) (count int, clue string, iname string, err error) { clueName := reduceCluetoinduce.ReplaceAllString( clueText, "" ) // get rid of clue-context (i.e. me./her. etc.) intentText = stripNonValidWords( db, personId, rasa.Entity{ Value: intentText, Entity: clueName }, analysed ) log.Printf( "Willing to save clue [%s] for %d with intentName %s as %s\n", clueName, personId, intentName, intentText) // we may adapt intent-name because of the clues we find if err := SaveAClue( db, intentText, clueName, personId, personModel ); err != nil { return 0, "", "", err } else { return 1, clueName, intentName, nil } } func FindGender( db *pg.DB, name string ) ( string, error ) { var gender string _, err := db.QueryOne( &gender, ` <<guess-gender:name>> `, name ) if err != nil && err == pg.ErrNoRows { return "", nil } return gender, err } // resultingValue := "" // for all words in slot.Value // pick it's analysed[ word ] // and check if this matches the required POSTag in the persona-clue // if so, add to resulting Value func stripNonValidWords( db *pg.DB, personId int, slot rasa.Entity, gramm frog.Sentence ) string { val := "" log.Printf( "stripping non valid words: [%s,%s]", slot.Entity, slot.Value ) required := findRequiredPostags( db, personId, slot.Entity ) if len( required ) == 0 { return slot.Value } log.Printf( "stripping non valid words, required: %v", required ) for _, word := range strings.Split( slot.Value, " " ) { if tok, ok := gramm[ word ]; ok { for _, postag := range required { if strings.Index( tok.POSTag, postag ) != -1 { val = val + " " + word } } } else { val = val + " " + word } } log.Printf( "stripped non valid words: [%s,%s]", slot.Entity, strings.TrimSpace( val ) ) return strings.TrimSpace( val ) } // here we try to check whether name is a persons name by seeking a gender for this name. // If this name has no gender, it is not a name. func tryNameClue( db *pg.DB, name string, personId int, personModel string, ) (count int, err error) { if gender, err := FindGender( db, name ); err != nil { fmt.Fprintf( os.Stderr, "tryNameClue found no gender for [%s] for [%d]\n", name, personId ) return count, err } else if gender != "" { fmt.Fprintf( os.Stderr, "tryNameClue naam found [%s] for [%d]\n", name, personId ) if err = SaveAClue( db, name, "naam", personId, personModel ); err != nil { if err == pg.ErrNoRows { fmt.Fprintf( os.Stderr, "tryNameClue 1 did not save clue: [%s] [%s] for [%d], is it missing?\n", "naam", name, personId ) } return count, err } count += 1 fmt.Fprintf( os.Stderr, "tryNameClue geslacht found [%s] for [%d]\n", gender, personId ) if err = SaveAClue( db, gender, "geslacht", personId, personModel ); err != nil { if err == pg.ErrNoRows { fmt.Fprintf( os.Stderr, "tryNameClue 2 did not save clue: [%s] [%s for [%d], is it missing?\n", "geslacht", gender, personId ) } return count, err } } return count, nil } // we are smarter than this, aren't we? var tn2dig = map[string]int{ "een": 1, "twee": 2, "drie": 3, "vier": 4, "vijf": 5, "zes": 6, "zeven": 7 , "zeuven": 7 , "acht": 8, "negen": 9, "tien": 10, "elf": 11, "twaalf": 12, "twaluf": 12, "dertien": 13, "veertien": 14, "vijftien": 15, "zestien": 16, "zeventien": 17 , "zeuventien": 17 , "achttien": 18, "negentien": 19, "twintig": 20, "eenentwintig": 21, "tweeentwintig": 22, "drieentwintig": 23, "vierentwintig": 24, "vijfentwintig": 25, "zesentwintig": 26, "zevenentwintig": 27, "zeuvenentwintig": 27, "achtentwintig": 28, "negenentwintig": 29, "dertig": 30, "eenendertig": 31, "tweeendertig": 32, "drieendertig": 33, "vierendertig": 34, "vijfendertig": 35, "zesendertig": 36, "zevenendertig": 37, "zeuvenendertig": 37, "achtendertig": 38, "negenendertig": 39, "veertig": 40, "eenenveertig": 41, "tweeenveertig": 42, "drieenveertig": 43, "vierenveertig": 44, "vijfenveertig": 45, "zesenveertig": 46, "zevenenveertig": 47, "zeuvenenveertig": 47, "achtenveertig": 48, "negenenveertig": 49, "vijftig": 50, "eenenvijftig": 51, "tweeenvijftig": 52, "drieenvijftig": 53, "vierenvijftig": 54, "vijfenvijftig": 55, "zesenvijftig": 56, "zevenenvijftig": 57, "zeuvenenvijftig": 57, "achtenvijftig": 58, "negenenvijftig": 59, "zestig": 60, "eenenzestig": 61, "tweeenzestig": 62, "drieenzestig": 63, "vierenzestig": 64, "vijfenzestig": 65, "zesenzestig": 66, "zevenenzestig": 67, "zeuvenenzestig": 67, "achtenzestig": 68, "negenenzestig": 69, } func tryAgeClue( db *pg.DB, word string, personId int, personModel string, ) (int, error) { var age int var err error if age, err = strconv.Atoi( word ); err != nil { age = tn2dig[ word ] } fmt.Fprintf( os.Stderr, "tryAgeClue found %d for %s\n", age, word ) if age > 6 && age < 80 { if err = SaveAClue( db, strconv.Itoa( age ), "leeftijd", personId, personModel ); err != nil { if err == pg.ErrNoRows { fmt.Fprintf( os.Stderr, "tryAgeClue did not save clue: %s %s for %d, is it missing?\n", "leeftijd", word, personId ) } return 0, err } return 1, nil } else { return 0, nil } }
3.4.6.4.1 Resolving clue-references
3.4.6.5 Texts
package texts import ( "os" "fmt" "github.com/go-pg/pg" "regexp" "log" ) type Texts struct { Id int Direction string Type string Content string Model string Positivematch string Negativematch string Intent string Cluetoinduce string Active bool Modifier string } func (rcvr *Texts) IsQuestion () bool { return rcvr.Type == "?" } func TopTexts( db *pg.DB, model string, intent string, personaId int, personId int, clue string ) ( []Texts, error ) { var texts []Texts type parm struct { Intent string Model string Persona int Person int Clue string } log.Printf( "(pinteresque) TopTexts(%d, %d, %s, %s, %s )", personId, personaId, clue, model, intent ) actual := parm{ Intent: intent, Model: model, Persona: personaId, Person: personId, Clue: clue} _, err := db.Query( &texts, ` <<top-matching-output-text:intent,model,persona,person,clue>> `, actual ) return texts, err } func GetText( db *pg.DB, content string, model string ) (Texts, error) { var thetext Texts _, err := db.Query( &thetext, ` <<get-text:content,model>> `, content, model ) fmt.Fprintf( os.Stderr, "Returning GetText: %v?\n", thetext ) return thetext, err } func StartText( db *pg.DB, model string ) (Texts, error) { var thetext Texts _, err := db.Query( &thetext, ` <<start-text:model>> `, model ) fmt.Fprintf( os.Stderr, "Returning StartText: %v with error [%v]?\n", thetext, err ) return thetext, err } func GoingAwayText( db *pg.DB, model string ) (Texts, error) { var thetext Texts _, err := db.Query( &thetext, ` <<byebye-text:model>> `, model ) fmt.Fprintf( os.Stderr, "Returning GoingAwayText: %v with error [%v]?\n", thetext, err ) return thetext, err } // calling func (rcvr *Texts) ReduceText( db *pg.DB, personaId int, personId int, model string ) string { type parm struct { Content string Persona int Person int Model string } actual := parm{ Content: rcvr.Content, Persona: personaId, Person: personId, Model: model} newtext := rcvr.Content for HasClueRefs( newtext ) { actual.Content = newtext _, err := db.Query( &newtext, ` <<reduce-text:text,persona,person,model>> `, actual ); if err != nil { fmt.Fprintf( os.Stderr, "Bailing out in ReduceText, error: %v\n", err ) return actual.Content } if actual.Content == newtext { // nothing more to do return actual.Content } actual.Content = newtext } return actual.Content } func HasClueRefs( content string ) bool { if matched, err := regexp.MatchString("<<go-match-clueref>>", content ); err != nil { return false } else { return matched } } func TextForSolvingClue( db *pg.DB, clueName string, model string ) ( Texts, error ) { var thetext Texts _, err := db.Query( &thetext, ` <<text-for-clue:cluename,model>> `, clueName, model ) fmt.Fprintf( os.Stderr, "Returning TextForClue: %v?\n", thetext ) return thetext, err } func Output( gender string, output string ) { if output != "" { fmt.Printf( gender + " " + output ) fmt.Printf( "\n" ) } }
3.4.6.6 Trail
Pinteresque logt alle activiteiten in een trail. Dat dient verschillende doelen:
[ ]rapporteer na het gebruik aan de gebruiker wat Pinteresque over hem of haar weet. Een opsomming van de clues volstaat mogelijk, maar het gehele gesprek kan opnieuw gereproduceerd worden met de audit-trail.[ ]voorkom het uitspreken van doublures. Elke PIntext die de persona gebruikt in het gesprek met de persoon wordt opgeslagen. Bij het zoeken naar de top 5 toepasselijke PIntexts worden eerder uitgesproken zinnen (die dus in de trail voorkomen) weggelaten.[ ]om Pinteresque te verbeteren is het noodzakelijk om gesprekken te kunnen beoordelen. Rapportage daarvoor is eenvoudig op basis van de trail te maken, inclusief namen en timestamps. Daarom wordt ook de intent-tekst opgeslagen, niet alleen wat de NLU-engine er van gemaakt heeft. Het is dan gemakkelijer om te beoordelen waar een eventueel probleem zit.
Een voorbeeldrapportje voor het gesprek dat persona Piet met persoon 121 voerde is:
select to_char( t.pit, 'mon-dd HH24:MI:SS' ) as tijdstip, t.intentname as intent, substring( replace(t.intent->>'text',E'\n',''), 1, 30 )||'...' as gehoord, substring( t.output, 1, 30 )||'...' as gesproken from trail t JOIN persons p ON p.id = t.person JOIN texts pt ON pt.id = t.pintext where person = 482 order by t.pit
| tijdstip | intent | gehoord | gesproken |
|---|---|---|---|
| may-19 15:50:02 | goedenmiddag, ik heet stephani… | ||
| may-19 15:50:07 | naam | ik heet piet… | hoe heet jij? … |
| may-19 15:50:10 | naam | piet… | mooie naam, piet. Kon je het g… |
| may-19 15:50:18 | verkeer | ja hoor, geen file… | Fijn dat je er bent. Je komt v… |
| may-19 15:50:22 | volgendevraag | dat is prima… | Kun je een voorbeeld geven van… |
| may-19 15:50:40 | taken-leider | ik kreeg een uitstaande factuu… | Kun je iets meer zeggen over d… |
| may-19 15:50:51 | taken-leider | ik bleef maar bellen naar die … | Vind je dat een essentieel ond… |
| may-19 15:51:02 | taken-initiatiefnemer | dat hoort erbij, alles wat nod… | Er zal vast wel eens wat mislu… |
| may-19 15:51:14 | taken-initiatiefnemer | ik ben weleens een factuur ver… | Heb je daar dan wel of juist g… |
| may-19 15:51:23 | taken-leider | zeker, dat onthoudt ik nog jar… | Dat is inderdaad fraai, kun je… |
| may-19 15:51:43 | none | Is dat altij de beste manier, … | |
| may-19 15:51:50 | taken-initiatiefnemer | nu ja, ik let nu veel beter op… | duidelijk. Kunnen we het over … |
| may-19 15:52:03 | taken-leider | dat is altijd leuk geweest, ge… | Kan dat in elke situatie? Omsc… |
| may-19 15:52:19 | taken-leider | als er gebuffeld moet worden, … | hum… |
| may-19 15:52:39 | none | mijn leeftijd is 39. en die va… | |
| may-19 15:52:43 | leeftijd | 34… | begrepen. medewerker finance h… |
package trail import ( "github.com/go-pg/pg" ) type Trail struct { Intentname string Persona int Person int Clue int Pintext int Intent string // is a json object Output string } func AddToTrail( db *pg.DB, persona int, person int, pintext int, intentname string, intent string, output string ) error { var row Trail row.Intentname = intentname row.Persona = persona row.Person = person row.Pintext = pintext row.Intent = intent row.Output = output _, err := db.QueryOne( &row, ` <<add-to-trail:persona,person,pintext,intentname,intent,output>> `, row ) return err }
3.4.7 TTS
ReadSpeaker doet dat (huis ter heide), maar Google Cloud API kan het ook; zie https://github.com/GoogleCloudPlatform/golang-samples/blob/master/texttospeech/synthesize_text/synthesize_text.go voor een sample waarmee we aplay kunnen aansturen. Twee clients, eentje manlijk en eentje vrouwelijk.
Totdat dit functioneert is bin/tts een doorgeefluik naar
espeak. Espeak ondersteunt geen gender in het Nederlands. De
gender variabele wordt genegeerd.
model=<<default-model>> [ "$1" != "" ] && model="$1" SPKDEVICEOPTION="-D ${SPKDEVICE}" [ "$SPKDEVICE" = "" ] && SPKDEVICEOPTION="" [ "$MICCONTROLLER" = "" ] && MICCONTROLLER=0 [ "$MICNAME" = "" ] && MICNAME=Capture [ "$SPEECHSRATE" = "" ] && SPEECHSRATE="<<audio-samplerate>>" trap "amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap" 0 INT PIPE TERM #playbackrate=`expr $SPEECHSRATE "*" 10 / 12` # we need a voice speaking faster for RS sed -u 's/[ ]*$//' | while read gender line do [ -p /tmp/terminal ] && [ "$line" = "tput clear" ] && ((tput -T linux clear; echo) > /tmp/terminal)& [ "$line" = "tput clear" ] && continue bin/todisplay "Not listening" & amixer -c ${MICCONTROLLER} -q set ${MICNAME} nocap #google speech api: hashed=`echo "$gender $line ${SPEECHSRATE} <<audio-format>> <<audio-filetype>>" | md5sum | awk '{print $1}'` if [ -r logs/${hashed}.wav ] then cat logs/${hashed}.wav else echo "[$gender] [$line] [${SPEECHSRATE}] [<<audio-format>>] [<<audio-filetype>>]~[$hashed]" >> logs/hashes ./texttospeech "$gender" "$line" | tee logs/${hashed}.wav fi | aplay ${SPKDEVICEOPTION} -q -r ${SPEECHSRATE} -f <<audio-format>> -t <<audio-filetype>> -- >/dev/null #readspeaker speech api: #./texttospeech-rs "$gender" "$line" | aplay -q -r "$playbackrate" -f <<audio-format>> -t <<audio-filetype>> -- amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap bin/todisplay "Listening" & echo "$line" done
Het uitzetten van de microfoon is noodzakelijk, omdat de spraak anders wordt opgepakt als input. Er zit nu echter een korte periode tussen een uitgesproken gespreksbot en het aanzetten van de microfoon. Als de andere spreker te vroeg begint, dan wordt een deel van zijn of haar tekst dus gemist.
Merk op dat twee API's worden gebruikt. Die van ReadSpeaker wordt iets sneller afgespeeld dan normaal.
De amixer-commando's kunnen weggehaald worden indien het gesprek
plaatsvindt met een hoofdtelefoon of een telefoon-hoorn. Er is dan
namelijk geen sprake van eigen spraak-feedback de microfoon
in. Probeer dit eerst uit, want er is vaak toch sprake van veel
overspraak, de gespreksbot gaat dan zelf met haar eigen teksten
aan de haal.
3.4.7.1 TTS met de ReadSpeaker API
TTS met wget, wat wil je nog meer:
wget -O vertelme.mp3 "https://tts.readspeaker.com/a/speak?key=562485849bd8600f8288408e2288ec84cf&lang=nl_nl&text=vertelme&voice=Guus"
Dat is echter traag en vergt veel file I/O. Beter is een GO-programma dat de API gebruikt en PCM naar output stuurt.
De
ReadSpeaker
documentatie is overigens prima in orde. Direct copy/paste naar
wget werkt. Er zijn helaas geen code-voorbeelden in andere
talen. Voor GO is ie hieronder.
package main // for checking credits use: wget -q -O - "https://tts.readspeaker.com/a/speak?key=$RSAPIKEY&command=credits" | grep amount // for checking speakers use: wget -q -O - "https://tts.readspeaker.com/a/speak?key=$RSAPIKEY&command=speakers" // for checking voices use: wget -q -O - "https://tts.readspeaer.com/a/speak?key=$RSAPIKEY&command=voiceinfo" // forc checking statistics use: wget -q -O - "https://tts.readspeaer.com/a/speak?key=$RSAPIKEY&command=statistics" import ( "log" "io" "os" "errors" "strings" "gopkg.in/resty.v1" ) func main() { voice := "Ilse" // the Dutch female voice text := "" switch len( os.Args ) { case 3: // gender and text given as parameter switch strings.ToLower( os.Args[ 1 ] ) { case "m", "♂", "": voice = "Guus" text = os.Args[ 2 ] case "v", "♀", "f": voice = "Ilse" text = os.Args[ 2 ] default: text = text + os.Args[ 1 ] + " " + os.Args[ 2 ] } } key := os.Getenv( "RSAPIKEY" ) if len( key ) < 10 { log.Printf( "Bad RSAPIKEY set in Environment\n" ) panic( errors.New( "NO RSAPIKEY set" ) ) } resp, err := resty. SetRedirectPolicy(resty.FlexibleRedirectPolicy(5)). R(). SetQueryParams(map[string]string{ "key" : key, "lang" : <<readspeaker-speech-lang-tag>>, "voice" : voice, "text" : text, "audioformat" : "<<readspeaker-audio-format>>", "samplerate" : "<<audio-samplerate>>", "streaming" : "0", }). SetDoNotParseResponse( true ). Get( "http://tts.readspeaker.com/a/speak" ) if err != nil { log.Printf( "Error received from Readspeaker API: [%v]", err) } else { reader := resp.RawBody() buf := make( []byte, 256 ) for { var nread int if n, err := reader.Read( buf ); err != nil && err != io.EOF { panic( err ) } else { nread = n } if nread > 0 { if _, err := os.Stdout.Write( buf[ :nread ] ); err != nil { panic( err ) } } else { reader.Close() break } } } }
Merk op dat er voor de audio-output een kleine buffer wordt
gebruikt. Dit is om ervoor te zorgen dat het lezende programma (bijvoorbeeld
aplay) direct kan beginnen met het verzorgen van
audio. Natuurlijk is het beter om de precieze minimale block-size
van 16kHz raw PCM te gebruiken; dat moet nog uitgezocht worden.
3.4.7.2 TTS met de Google API
Het
Google voorbeeld van TTS
schrijft naar een output file, dat
is in figuur 39 gewijzigd in Stdout. Verder wordt de
gender vastgesteld op basis van het eerste command-line
argument (mits er een tweede is). Het tweede is dan de tekst. In
script 37 wordt het gebruik getoond.
package main import ( "context" "os" "log" "strings" "errors" texttospeech "cloud.google.com/go/texttospeech/apiv1" texttospeechpb "google.golang.org/genproto/googleapis/cloud/texttospeech/v1" ) func main() { ctx := context.Background() client, err := texttospeech.NewClient(ctx) if err != nil { log.Fatal(err) } encodingname := "LINEAR16" sampleratename := "16k" gendersign := "f" text := "" voicename := "nl-NL-Wavenet-A" if len( os.Args ) == 5 { encodingname = os.Args[ 1 ] sampleratename = os.Args[ 2 ] gendersign = strings.ToLower( os.Args[ 3 ] ) text = os.Args[ 4 ] } if len( os.Args ) == 4 { encodingname = os.Args[ 1 ] gendersign = strings.ToLower( os.Args[ 2 ] ) text = os.Args[ 3 ] } if len( os.Args ) == 3 { gendersign = strings.ToLower( os.Args[ 1 ] ) text = os.Args[ 2 ] } if len( os.Args ) == 2 { text = os.Args[ 1 ] } gender := texttospeechpb.SsmlVoiceGender_FEMALE switch gendersign { case "m", "♂", "": gender = texttospeechpb.SsmlVoiceGender_MALE case "v", "♀", "f": gender = texttospeechpb.SsmlVoiceGender_FEMALE default: // no gender sign, we'll just speak it if len( os.Args ) == 3 { text = os.Args[ 1 ] + " " + os.Args[ 2 ] } } audioencoding := texttospeechpb.AudioEncoding_<<google-audio-format>> switch encodingname { // see https://cloud.google.com/speech-to-text/docs/encoding case "MP3": audioencoding = texttospeechpb.AudioEncoding_MP3 case "LINEAR16": audioencoding = texttospeechpb.AudioEncoding_LINEAR16 case "OGG_OPUS": audioencoding = texttospeechpb.AudioEncoding_OGG_OPUS default: log.Fatal( errors.New( "Unsupported audioencoding selected" ) ) } var samplerate int32 samplerate = 16000 switch sampleratename { // see https://cloud.google.com/speech-to-text/docs/encoding case "8k", "8000": samplerate = 8000 case "16k", "16000": samplerate = 16000 case "32k", "32000": samplerate = 32000 case "48k", "48000": samplerate = 48000 default: log.Fatal( errors.New( "Unsupported samplerate selected" ) ) } // somehow, the google text-to-speech API doesnt need the samplerate if samplerate < 0 { log.Printf( "Samplerate is %d, but is not used by the API\n", samplerate ) } var req texttospeechpb.SynthesizeSpeechRequest // very strange, if i set Name in voiceselectionparams, the male voice cannot be used, hence the following trick if gender == texttospeechpb.SsmlVoiceGender_MALE { req = texttospeechpb.SynthesizeSpeechRequest{ Input: &texttospeechpb.SynthesisInput{ InputSource: &texttospeechpb.SynthesisInput_Text{Text: text }, }, Voice: &texttospeechpb.VoiceSelectionParams{ LanguageCode: "<<lang-tag>>-<<region-tag>>", SsmlGender: gender, }, AudioConfig: &texttospeechpb.AudioConfig{ AudioEncoding: audioencoding, }, } } else { req = texttospeechpb.SynthesizeSpeechRequest{ Input: &texttospeechpb.SynthesisInput{ InputSource: &texttospeechpb.SynthesisInput_Text{Text: text }, }, Voice: &texttospeechpb.VoiceSelectionParams{ LanguageCode: "<<lang-tag>>-<<region-tag>>", Name: voicename, SsmlGender: gender, }, AudioConfig: &texttospeechpb.AudioConfig{ AudioEncoding: audioencoding, }, } } resp, err := client.SynthesizeSpeech(ctx, &req) if err != nil { log.Fatal(err) } os.Stdout.Write( resp.AudioContent ) }
Merk op dat er mbt geslacht op M of m voor manlijk en V, v,
F, f voor vrouwlijk wordt getoetst (en natuurlijk op de symbolen
ervoor). Indien geen gender wordt meegegeven, dan wordt
verondersteld dat het om uit te spreken tekst gaat. Een
gender-argument dat leeg is (waarschijnlijk als gevolg van een
foute aanroep) impliceert manlijk.
De Wavenet versie van de stem is een stuk beter dan de gewone. Helaas ontbreekt daarvoor de mannelijke stem.
3.4.8 Audio onder Linux
De robot Pinteresque gebruikt twee audio-kaarten. Een Seeed-2mic-voicecard voor omgevings-spraak en een luidspreker die de omgeving laat horen wat de bot zegt en een USB Audio DAC voor gebruik met een telefoon-hoorn (dat is een ding dat je tegen je hoofd houdt met een microfoon voor je mond en een luidspreker bij je oor). Dat laatste gebeurt bij gebruik in de Selection Automat.
aplay -l levert voor deze twee kaarten op (voor afspelen van audio):
card 1: Device [C-Media USB Audio Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0 card 2: seeed2micvoicec [seeed-2mic-voicecard], device 0: bcm2835-i2s-wm8960-hifi wm8960-hifi-0 [] Subdevices: 1/1 Subdevice #0: subdevice #0
En arecord -l (voor opnemen van audio):
card 1: Device [C-Media USB Audio Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0 card 2: seeed2micvoicec [seeed-2mic-voicecard], device 0: bcm2835-i2s-wm8960-hifi wm8960-hifi-0 [] Subdevices: 1/1 Subdevice #0: subdevice #0
Voor het al of niet aanzetten van de microfoon wordt amixer dus
aangeroepen met -c 1 voor de USB Audio en -c 2 voor de
Seeed-kaart.
De microfoon wordt aan of uitgezet met -q set <MICNAME> nocap,
waarbij <MICNAME> voor de USB Audio 'Mic' is en voor de
Seeed-kaart 'Capture'.
3.4.8.1 arecord
Omdat devices nogal eens van positie wisselen is het beter om
gebruik te maken van logische namen. arecord -L levert die voor
de microfoon:
sysdefault:CARD=Device
C-Media USB Audio Device, USB Audio
Default Audio Device
front:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Front speakers
surround21:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
2.1 Surround output to Front and Subwoofer speakers
surround40:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
4.0 Surround output to Front and Rear speakers
surround41:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
4.1 Surround output to Front, Rear and Subwoofer speakers
surround50:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
5.0 Surround output to Front, Center and Rear speakers
surround51:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
5.1 Surround output to Front, Center, Rear and Subwoofer speakers
surround71:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
7.1 Surround output to Front, Center, Side, Rear and Woofer speakers
iec958:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
IEC958 (S/PDIF) Digital Audio Output
dmix:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct sample mixing device
dsnoop:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct sample snooping device
hw:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct hardware device without any conversions
plughw:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Hardware device with all software conversions
sysdefault:CARD=seeed2micvoicec
seeed-2mic-voicecard,
Default Audio Device
dmix:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct sample mixing device
dsnoop:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct sample snooping device
hw:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct hardware device without any conversions
plughw:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Hardware device with all software conversions
Voor gebruik in de Selection Automat kiezen we voor:
dsnoop:CARD=Device,DEV=0. Omdat het USB Audio device niet anders
dan met 48k kan samplen, gebruiken we een sample-rate van 48k naar
voor de speech-to-text. Pinteresque gebruikt de Seeed-kaart en
kan wel met 16k samplen, meer dan voldoende voor spraak. Er gaat
dus 16k audio naar de speech-to-text dienst op Internet (Google
Cloud).
Capturing op de Selection Automat gebeurt dus met:
arecord -D dsnoop:CARD=Device,DEV=0 -r 48000 -c 1 -f S16_LE -t raw -q - < /dev/null | ./livecaption -e LINEAR16 -r 48k
3.4.8.2 aplay
Voor aplay -L geldt dan:
null
Discard all samples (playback) or generate zero samples (capture)
default
playback
capture
dmixed
array
sysdefault:CARD=ALSA
bcm2835 ALSA, bcm2835 ALSA
Default Audio Device
dmix:CARD=ALSA,DEV=0
bcm2835 ALSA, bcm2835 ALSA
Direct sample mixing device
dmix:CARD=ALSA,DEV=1
bcm2835 ALSA, bcm2835 IEC958/HDMI
Direct sample mixing device
dsnoop:CARD=ALSA,DEV=0
bcm2835 ALSA, bcm2835 ALSA
Direct sample snooping device
dsnoop:CARD=ALSA,DEV=1
bcm2835 ALSA, bcm2835 IEC958/HDMI
Direct sample snooping device
hw:CARD=ALSA,DEV=0
bcm2835 ALSA, bcm2835 ALSA
Direct hardware device without any conversions
hw:CARD=ALSA,DEV=1
bcm2835 ALSA, bcm2835 IEC958/HDMI
Direct hardware device without any conversions
plughw:CARD=ALSA,DEV=0
bcm2835 ALSA, bcm2835 ALSA
Hardware device with all software conversions
plughw:CARD=ALSA,DEV=1
bcm2835 ALSA, bcm2835 IEC958/HDMI
Hardware device with all software conversions
sysdefault:CARD=Device
C-Media USB Audio Device, USB Audio
Default Audio Device
front:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Front speakers
surround21:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
2.1 Surround output to Front and Subwoofer speakers
surround40:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
4.0 Surround output to Front and Rear speakers
surround41:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
4.1 Surround output to Front, Rear and Subwoofer speakers
surround50:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
5.0 Surround output to Front, Center and Rear speakers
surround51:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
5.1 Surround output to Front, Center, Rear and Subwoofer speakers
surround71:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
7.1 Surround output to Front, Center, Side, Rear and Woofer speakers
iec958:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
IEC958 (S/PDIF) Digital Audio Output
dmix:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct sample mixing device
dsnoop:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct sample snooping device
hw:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Direct hardware device without any conversions
plughw:CARD=Device,DEV=0
C-Media USB Audio Device, USB Audio
Hardware device with all software conversions
sysdefault:CARD=seeed2micvoicec
seeed-2mic-voicecard,
Default Audio Device
dmix:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct sample mixing device
dsnoop:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct sample snooping device
hw:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Direct hardware device without any conversions
plughw:CARD=seeed2micvoicec,DEV=0
seeed-2mic-voicecard,
Hardware device with all software conversions
Voor gebruik in de Selection Automat gebruiken we:
plughw:CARD=Device,DEV=0.
De text-to-speech zal dus uiteindelijk aplay gebruiken op de
volgende manier:
aplay -D plughw:CARD=Device,DEV=0 -q -r 48000 -f S16_LE -t raw -- >/dev/null
Omdat volume een probleem kan zijn wordt het eenmalig, bij starten van Pinteresque, op het juiste niveau ingesteld. Dat kan met:
Voor de USB Audio wordt gebruikt:
amixer -c 1 set Speaker 90%,90%
3.4.9 Taal en Audio-eigenschappen
Pinteresque gebruit verscheidene onderdelen voor de verwerking van
audio. Tussen arecord en livecaption en tussen texttospeech
en aplay gaat ruwe audio, 16 bits, little-endian met een
sampling rate van 16kHz. Omdat de onderdelen samen moeten kunnen
werken, worden deze audio-eigenschappen hier gegroepeerd. Er is
gekozen voor een enkel audio-formaat, strikt genomen moet dat
niet. Tussen arecord en livecaption kan een ander formaat
gebruikt worden dan tussen texttospeech en aplay, maar dan is
het niet meer mogelijk om, bij experimenten of troubleshooting, de
output van arecord door te sturen naar die van aplay.
Zie de scripts in figuur 20 en 37, en de GO-programma's 21 en 39.
16000
S16_LE
LINEAR16
pcm
raw
In de programma's livecaption en texttospeech moeten deze
waardes, maar dan vertaald naar Google API-constantes, gebruikt
worden voor respectievelijk input en output. Merk op dat S16_LE
en LINEAR16 op hetzelfde formaat doelen, maar zo verschillen
zijn dat ze apart opgenomen zijn. De eerste is een parameter voor
arecord en aplay en de tweede is een
audio-configuratieparameter voor de Google Speech API.
We gebruiken Nederlands in onze gespreksbot, dat komt hier-en-daar
tot uiting. Er wordt gekozen voor Nederlands als taal (nl) en de
nederlandse cultuur (NL).
De language-tags worden gebruikt in figuren 21, 39 en 26.
nl
NL
De language-tag die door Google Speech gebruikt is een combinatie van de language en region (zoals beschreven in RFC 5646).
"<<lang-tag>>-<<region-tag>>"
De language-tag die door ReadSpeaker gebruikt is ook een combinatie
van de language en region, maar
dan lowercase en met _ ipv -.
strings.ToLower( "<<lang-tag>>_<<region-tag>>" )
3.4.10 Het side-channel
Pinteresque als kappersklant functioneert alleen en zonder enige hulpmiddelen anders dan een knop voor het aanzetten. Soms is er de wens om met informatie uit de omgeving het model te wisselen, een gesprek te herstarten of om de temperatuur en hoeveelheid licht een rol te laten spelen in het gesprek. Mogelijk wordt er aan het einde van een gesprek een rapport afgedrukt.
Daarvoor is het side-channel, een programma dat deze
omgevingsinput meeneemt en naar het NLU onderdeel van de pipe-line
stuurt. Die commando's bestaan uit een prefix
(ofwel #!),
een commando en eventuele
parameters. Vooralsnog worden alleen model voor het starten van
een gesprek met het te gebruiken model als parameter ondersteund
en end voor het beeïndigen van het gesprek.
Het script dat de uitvoer als extra naar NLU stuurt moet eerst uitzoeken wat het PID is van NLU, daarna wordt de juiste implementatie voor de toepassing gezocht en gestart. Indien er geen specifieke side-channel is, wordt er een model gestart.
[ "$THISBOT" = "sorry" ] && [ "$MOUSESIDE" = "" ] && MOUSESIDE=/dev/input/event0 while : do thepid=`ps xa | grep nlu-pipe | grep python | awk '{print $1}' | tail -1` if [ "$thepid" != "" ] then [ "$THISBOT" = "selectionautomat" ] && ./pin-sidechannel -d -r -m ir-bot -M ir-prs >> /proc/${thepid}/fd/0 [ "$THISBOT" = "sorry" ] && evtest ${MOUSESIDE} | ./mouse-sidechannel -b KEY_PLAYPAUSE -B KEY_NEXTSONG -m sorry >> /proc/${thepid}/fd/0 [ "$THISBOT" = "pinteresque" ] && ./pin-sidechannel -d -B 0 -m kappersklant -M "" >> /proc/${thepid}/fd/0 # echo "<<nlu-command-prefix>><<nlu-model-command>> ir-bot" >> /proc/${thepid}/fd/0 sleep 1 # wait for the GPIO-ports to settle continue # and then retry after settling else sleep 2 # wait for the nlu-pipe to appear, it is python, so wait long fi done
Het side-channel stuurt stdout naar de stdin van de NLU-pipe. Die ontvangt op stdin al tekst van de spraakherkenning, met de command-prefix worden de commando's onderscheiden van de door te geven teksten. ▮
Het sidechannel kan gebruikt worden om de bot te starten (door het juiste command te injecteren) en om speciale hardware-signalen te vertalen naar commando's.
In eerste instantie is een sidechannel gemaakt voor het oppakken triggers op de GPIO pinnen. Later eentje die mouse-buttons leest.
3.4.10.1 De GPIO versie
Voor de specifieke toepassing als sollicitatierobot (in geval
$THISBOT gelijk is aan selectionautomat) is er
sprake van:
[X]telefoonhoorn wordt opgenomen
het gesprek start met een nieuw model, keuze uit twee modellen: kandidaat initieert en interviewer initieert. Het onderscheid komt doordat de eerste tijdens het rinkelen gebeurt.[X]telefoonhoorn wordt op de haak gelegd
het gesprek eindigt.[ ]een keuze voor een vacature wordt gemaakt
het bijbehorende model wordt gebruikt voor het volgende gesprek.[X]als er 20 minuten geen gesprek is geweest, ga dan rinkelen. stop met rinkelen als de hoorn wordt opgepakt.[X]na een einde gesprek (hoorn erop), wordt er gerapporteerd. Afhankelijk van de uitslag kunnen verschillende opties voorlprgebruikt worden. Te denken valt aan-o InputSlot=Rightvoor een rood etiket en-o InputSlot=Leftvoor het groene of blauwe etiket.
Het programma dat dit doet draait onafhankelijk van de bot-pipe-line, maar gebruikt stdin van de NLU om commando's te injecteren. Een en ander is vooralsnog niet gesynchroniseerd, dat betekent dat als een gebruiker side-channel gebeurtenissen veroorzaakt en ook nog eens praat, er corrupte input op NLU en ook Pinteresque verschijnt11.
package main import ( "os" "os/exec" "fmt" "time" "log" "github.com/davecheney/gpio" flg "github.com/jessevdk/go-flags" ) var options struct { Button1 int `short:"b" description:"Number of button 1" default:"17"` Button2 int `short:"B" description:"Number of button 2" default:"23"` Doreport bool `short:"d" description:"Call bin/preport at end-command"` NoEnding bool `short:"n" description:"No button will start the end-command"` Modelone string `short:"m" description:"Model to use upon user-action" env:"THISBOT"` Modeltwo string `short:"M" description:"Model to use upon user-reaction" env:"THISBOT"` Test bool `short:"t" description:"Testing: will print out button states every .5 seconds" env:"TESTING"` Ring bool `short:"r" description:"Use ringer to attract attention" env:"RINGER"` Verbose bool `short:"v" description:"Add some messaging to stderr" env:"VERBOSE"` } var but1 gpio.Pin // for handset var but2 gpio.Pin // for handset var relais gpio.Pin // for relay var berr error var moved1 = time.Unix( 0, 0 ) var moved2 = time.Unix( 0, 0 ) var StartRinging *time.Timer var runningdialogue = false var ringing = false func main() { _, err := flg.Parse( &options ) if err != nil { log.Printf( "(pin-sidechannel) Error parsing options: %v", err ) os.Exit( 1 ) } ButInit() if options.Ring { RelaisInit() Ring() // for feedback } if options.Test { if options.Ring { relais.Set() log.Printf( "Relais Set\n" ) } for { if options.Button1 != 0 { log.Printf( "But1 (%d): %v", options.Button1, but1.Get() ) } if options.Button2 != 0 { log.Printf( "But2 (%d): %v", options.Button2, but2.Get() ) } time.Sleep( 500 * time.Millisecond) } } if options.Button1 != 0 { But1handler( HandsetMoves ) } if options.Button2 != 0 { But2handler( HandsetMoves ) } if options.Ring { StartRinging = time.NewTimer( 20 * time.Minute ) } if options.Ring { go func() { for { _, ok := <- StartRinging.C if !ok { return } if !runningdialogue { ringing = true Ring() Ring() doDisplay( "Pick up to start" ) if !StartRinging.Stop() { <- StartRinging.C } } ringing = false StartRinging.Reset( 20 * time.Minute ) } }() } for { time.Sleep( 1 * time.Second ) } } func HandsetMoves() { if time.Now().Sub( moved1 )/time.Millisecond < 500 { return } But1handler( move ) //But2handler( move ) time.Sleep( 200 * time.Millisecond ) moved1 = time.Now() if options.Verbose { if but1 != nil { log.Printf( "Handset b1[%v]\n", but1.Get() ) } if but2 != nil { log.Printf( "Handset b2[%v]\n", but2.Get() ) } } if but1 != nil && but1.Get() == false && (!runningdialogue || options.NoEnding) { doDisplay( "Hook off" ) if !ringing { if options.Verbose { log.Printf( "Handset picked up, sending [%s%s]\n", "<<nlu-command-prefix>><<nlu-model-command>> ", options.Modelone ) } fmt.Printf( "<<nlu-command-prefix>><<nlu-model-command>> " + options.Modelone + "\n") } else { if options.Verbose { log.Printf( "Handset picked up, sending [%s%s]\n", "<<nlu-command-prefix>><<nlu-model-command>> ", options.Modeltwo ) } fmt.Printf( "<<nlu-command-prefix>><<nlu-model-command>> " + options.Modeltwo + "\n") } runningdialogue = true if options.Ring { StartRinging.Stop() } } if but1 != nil && but1.Get() == false && runningdialogue { } if but1 != nil && but1.Get() == true && !runningdialogue { doDisplay( "Pick up to start" ) } if but1 != nil && but1.Get() == true && runningdialogue { doDisplay( "Hook on" ) if !options.NoEnding { if options.Verbose { log.Printf( "Handset put down, sending [%s]\n", "<<nlu-command-prefix>><<nlu-end-command>>") } fmt.Printf( "<<nlu-command-prefix>><<nlu-end-command>>\n") runningdialogue = false StartRinging.Stop() _ = StartRinging.Reset( 20 * time.Minute ) if options.Doreport { log.Printf( "Starting report\n" ) doReport() } } } time.Sleep( 600 * time.Millisecond ) But1handler( HandsetMoves ) //But2handler( HandsetMoves ) moved1 = time.Now() } func move() { if options.Verbose { log.Printf( "Moved\n") if but1 != nil { log.Printf( "Handset b1[%v]\n", but1.Get() ) } if but2 != nil { log.Printf( "Handset b2[%v]\n", but2.Get() ) } } } func ButInit() { if but1 == nil && options.Button1 != 0 { but1, berr = gpio.OpenPin( options.Button1, gpio.ModeInput ) but1.BeginWatch( gpio.EdgeFalling, move ) } if but1 == nil && options.Button1 != 0 { panic( berr ) } if but2 == nil && options.Button2 != 0 { but2, berr = gpio.OpenPin( options.Button2, gpio.ModeInput ) but2.BeginWatch( gpio.EdgeFalling, move ) } if but2 == nil && options.Button2 != 0 { panic( berr ) } } func RelaisInit() { if relais == nil { relais, berr = gpio.OpenPin( 12, gpio.ModeOutput ) } if relais == nil { panic( berr ) } } func But1handler( handlerUp gpio.IRQEvent ) { if handlerUp == nil { but1.BeginWatch( gpio.EdgeBoth, move ) } else { but1.BeginWatch( gpio.EdgeRising, handlerUp ) } } func But2handler( handlerUp gpio.IRQEvent ) { if handlerUp == nil { but2.BeginWatch( gpio.EdgeBoth, move ) } else { but2.BeginWatch( gpio.EdgeRising, handlerUp ) } } func Ring() { // gpio 12, set 12 to high for ON for n:= 3; n >= 0; n -= 1 { if !runningdialogue { relais.Set() log.Printf( "Ringing\n" ) time.Sleep( 200 * time.Millisecond ) relais.Clear() if runningdialogue { break } log.Printf( "Silent\n" ) time.Sleep( 100 * time.Millisecond ) } ringing = false } } func doDisplay( s string ) { cmd := exec.Command( "bin/todisplay", s ) if err := cmd.Run(); err != nil { log.Printf( "Todisplay failed [%v]\n", err ) } } func doReport() { log.Printf( "Doing report now\n" ) cmd := exec.Command( "bin/preport" ) if err := cmd.Run(); err != nil { log.Printf( "Reporting failed [%v]\n", err ) } }
De volgende GPIO poorten worden op de 2-mic hat gebruikt (see https://pinout.xyz/pinout/respeaker_2_mics_phat):
| GPIO (BCM) | PIN | function |
|---|---|---|
| 0, 1, 2, 3 | 27, 28, 3, 5 | I2C-1 |
| 10, 11, 20, 21 | 19, 23, 38, 40 | SPI (leds) |
| 12, 13 | 32, 33 | grove / relais |
| ground | 9 | button ground/common |
| 17 | 11 | (button) hook off |
| 23 | 16 | hook on |
De poorten die gebruikt worden moeten van een pull-up weerstand worden voorzien. Dat kan met (0 is BCM17 en 4 is BCM23):
gpio -g mode 0 up gpio -g mode 4 up
Na herbouwen van de Selection Automat blijken de poorten
pull-down te zijn aangesloten. In plaats van up moet er dus down
worden gebruikt in /etc/rc.local.
3.4.10.2 De mouse-button versie
De mouse-button versie leest van stdin en schrijft nlu-commando's naar stdout. Het verschil met de GPIO versie is dus het interpreteren van de input kant.
Het tool evtest geeft output met:
Testing ... (interrupt to exit) Event: time 1610444568.429426, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70050 Event: time 1610444568.429426, type 1 (EV_KEY), code 105 (KEY_LEFT), value 1 Event: time 1610444568.429426, -------------- SYN_REPORT ------------ Event: time 1610444568.557436, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70050 Event: time 1610444568.557436, type 1 (EV_KEY), code 105 (KEY_LEFT), value 0 Event: time 1610444568.557436, -------------- SYN_REPORT ------------
Met grep kunnen we dat reduceren tot wat we willen zien in de
sidechannel implementatie (evtest /dev/input/event20 | grep EV_KEY ):
Event: time 1610445067.035050, type 1 (EV_KEY), code 105 (KEY_LEFT), value 1 Event: time 1610445067.154916, type 1 (EV_KEY), code 105 (KEY_LEFT), value 0
package main import ( "os" "os/exec" "fmt" "regexp" "bufio" "time" "log" flg "github.com/jessevdk/go-flags" ) var options struct { Button1 string `short:"b" description:"Name of button 1" default:"KEY_LEFT"` Button2 string `short:"B" description:"Name of button 2" default:"KEY_RIGHT"` Button3 string `short:"c" description:"Name of button 3" default:"KEY_NONE"` Doreport bool `short:"d" description:"Call bin/preport at end-command"` Modelone string `short:"m" description:"Model to use upon user-action" env:"THISBOT"` Verbose bool `short:"v" description:"Add some messaging to stderr" env:"VERBOSE"` } var moved1 = time.Unix( 0, 0 ) var moved2 = time.Unix( 0, 0 ) var moved3 = time.Unix( 0, 0 ) var moved4 = time.Unix( 0, 0 ) var moved5 = time.Unix( 0, 0 ) var runningdialogue = false func main() { _, err := flg.Parse( &options ) if err != nil { log.Printf( "(mouse-sidechannel) Error parsing options: %v", err ) os.Exit( 1 ) } ButInit() } func StartBot() { if time.Now().Sub( moved1 )/time.Millisecond < 500 { return } time.Sleep( 200 * time.Millisecond ) moved1 = time.Now() if options.Verbose { log.Printf( "Handset picked up, sending [%s%s]\n", "<<nlu-command-prefix>><<nlu-model-command>> ", options.Modelone ) } fmt.Printf( "<<nlu-command-prefix>><<nlu-model-command>> " + options.Modelone + "\n") time.Sleep( 600 * time.Millisecond ) moved1 = time.Now() } func StartEndTune() { if time.Now().Sub( moved2 )/time.Millisecond < 500 { return } if options.Modelone == "sorry" { cmd := exec.Command( "bin/nocap" ) if err := cmd.Run(); err != nil { log.Printf( "(mouse-sidechannel) nocap failed [%v]\n", err ) } } if options.Verbose { log.Printf( "Handset put down, sending [%s]\n", "<<nlu-command-prefix>><<nlu-end-command>>") } fmt.Printf( "<<nlu-command-prefix>><<nlu-end-command>>\n") time.Sleep( 600 * time.Millisecond ) moved2 = time.Now() } func doReport() { if time.Now().Sub( moved3 )/time.Millisecond < 500 { return } time.Sleep( 200 * time.Millisecond ) moved3 = time.Now() if options.Verbose { log.Printf( "Doing report now\n" ) } cmd := exec.Command( "bin/preport" ) if err := cmd.Run(); err != nil { log.Printf( "Reporting failed [%v]\n", err ) } time.Sleep( 600 * time.Millisecond ) moved3 = time.Now() } func doPowerdown() { if time.Now().Sub( moved4 )/time.Millisecond < 500 { return } moved4 = time.Now() log.Printf( "Doing shutdown now\n" ) cmd := exec.Command( "sudo", "shutdown", "-P", "now" ) if err := cmd.Run(); err != nil { log.Printf( "Shutting down failed [%v]\n", err ) } // notreached… time.Sleep( 600 * time.Millisecond ) moved4 = time.Now() } func doRestart() { if time.Now().Sub( moved5 )/time.Millisecond < 500 { return } moved5 = time.Now() log.Printf( "Doing restart pinteresque now\n" ) cmd := exec.Command( "sudo", "systemctl", "restart", "pinteresque" ) if err := cmd.Run(); err != nil { log.Printf( "Restarting Pinteresque failed [%v]\n", err ) } // notreached… time.Sleep( 600 * time.Millisecond ) moved5 = time.Now() } // match two things from "Event: time 1610445067.890861, type 1 (EV_KEY), code 105 (KEY_LEFT), value 0" // key and value var mouseline = regexp.MustCompile( "Event:.*, type . .(EV_[A-Z]*)., code [0-9]* .(KEY_[A-Z]*)., value ([0-9a-f]*)") func ButInit() { r := bufio.NewReader( os.Stdin ) for s, err := r.ReadString( '\n' ); err == nil; s, err = r.ReadString( '\n' ) { if options.Verbose { log.Printf( "(mouse-sidechannel) on input: %s", s ) } if len( s ) <= 6 { log.Printf( "(mouse-sidechannel) reading a line too short %s, ignoring it", s ) continue } matches := mouseline.FindStringSubmatch( s ) if matches == nil || len( matches ) != 4 { if options.Verbose { log.Printf( "(mouse-sidechannel) no match reading line %s, ignoring it", s ) } continue } inputtype := matches[ 1 ] keyname := matches[ 2 ] inputvalue := matches[ 3 ] if options.Verbose { log.Printf( "(mouse-sidechannel) mouse has ([%s],[%s],[%s])", inputtype, keyname, inputvalue ) } // only go to work for inputvalue 0, which is button-release. switch keyname { case options.Button1: if inputvalue == "0" { StartBot() } case options.Button2: if inputvalue == "0" { StartEndTune() } case options.Button3: if inputvalue == "0" { doReport() } case "KEY_POWER": if inputvalue == "0" { doPowerdown() } case "KEY_HOMEPAGE": if inputvalue == "0" { doRestart() } default: log.Printf( "(mouse-sidechannel) (%s,%s,%s) not handled", inputtype, keyname, inputvalue ) } } if options.Verbose { log.Printf( "(mouse-sidechannel) finished input" ) } }
3.4.11 Het display
Pinteresque als kappersklant kent geen display, maar de Selection Automat wel.
Het script todisplay verzorgt de toegang tot het display op de
bot.
[ "$THISBOT" != "selectionautomat" ] && echo "todisplay: $*" 1>&2 && exit 0 [ -w /dev/ttyACM0 ] && printf "%-25s\n" "$*" > /dev/ttyACM0
Om het display te kunnen gebruiken moet er aan /etc/rc.local
toegevoegd worden:
chmod a+rw /dev/ttyACM0 stty -F /dev/ttyACM0 -hupcl stty -F /dev/ttyACM0 ispeed 9600 ospeed 9600 -ignpar cs8 -cstopb -echo
Het display hangt aan een Arduino met de volgende code daarin; die wordt over serial door de Pi aangestuurd:
#include <Wire.h> #include <hd44780.h> #include <hd44780ioClass/hd44780_I2Cexp.h> hd44780_I2Cexp lcd; //define lcd const int LCD_COLS = 13; // amount of character per row const int LCD_ROWS = 2; // amount of rows #include <RBDdimmer.h>// #define USE_SERIAL Serial #define outputPin 3 // #define zerocross 2 //z-c to pin 2 of arduino dimmerLamp dimmer(outputPin); String a; void setup() { Serial.begin(9600); //start listening on port 9600 lcd.begin(LCD_COLS, LCD_ROWS); //start lcd lcd.print("pick up"); //welcome message lcd.setCursor(0,1); lcd.print("to start"); USE_SERIAL.begin(9600); dimmer.begin(NORMAL_MODE, ON); //start ac dimmer bel } void loop() { if (Serial.available() > 0) { a= Serial.readString();// read the incoming data from rpi String first = a.substring(0,12); //split up data for lcd row 1 String last = a.substring(12,25); //split up data for lcd row 2 lcd.clear(); //clear lcd when serial message is received lcd.setCursor(0,0); lcd.print(first); //print first row to lcd lcd.setCursor(0,1); lcd.print(last); //print second row to lcd delay(100); } dimmer.setPower(40); //bel percentage }
See substring() documentation for the parameter semantics.
3.5 Installatie en voorzieningen
Een standaard Raspbian of Debian installatie moet voorzien worden van enkele extra's om gebruikt te kunnen worden voor Pinteresque.
Om te beginnen is het verstandig het OS dat draait te vernieuwen:
apt update apt upgrade
Indien het OS gebaseerd is op Snips, dan moeten de snips-services gestopt en weggehaald worden, met tab-completion kun je door alle :
for serv in analytics audio-server snips-hotword skill-server asr dialogue nlu tts injection do systemctl disable snips-${serv}.service systemctl stop snips-${serv}.service done
3.5.1 Starten van Pinteresque
Omdat de orchestrator ergens middenin een pipe-line zit is er een
enkele startregel met een aantal pipes (|).
[ ! -d logs ] && mkdir logs dtmark=$(date -Ins) ipaddress=`hostname -I | awk '{print $1}'` psql -q -d pin -h localhost -c " update clues set value='$ipaddress' where name = 'ipaddress' and person in (select id from persons where isrobot)" bin/asr "${MODEL}" | bin/nlu "${MODEL}" | bin/anno "${MODEL}" | \ ./pinteresque -m "${MODEL}" $TESTING | bin/tts "${MODEL}"
Om het ip-adres mondeling te kunnen vragen aan de bot, wordt een clue voorbereid met daarin het eerste ip-adres. Het model krijgt automatisch een intent om met dit persona adres te antwoorden.
Die clue met ip-adres wordt in de persona's gezet, waardoor de person-rows uiteindelijk het ip-adres van de sessie ontvangen. ▮
bin/asr (zie figuur 20) gebruikt de microfoon en
levert na elke pauze van de spreker een regel tekst op.
bin/nlu (zie figuur 27) levert per invoer-regel een
JSON-object per regel; die wordt aan het pinteresque-programma
aangeboden.
bin/anno (zie figuur 28 voorziet de tekst van
per-word-analyses over de grammaticale rol in de zin.12
bin/tts (zie figuur 37 spreekt elke regel die
binnenkomt uit. Dit onderdeel van de pipe-line is ook
verantwoordelijk voor het uit- en weer aanzetten van de
microfoon.
De componenten kunnen ook los gebruikt worden om te toetsen of NLU wel goed getraind is. Dat geldt ook voor ASR. Het programma pinteresque vereist JSON op input, dus dat typt wat lastig. TTS daarentegen, wil niet meer weten dan het geslacht van de spreker en de tekst die uitgesproken wordt. Een TTS-regel begint met =v = of =m = om de spreker (respectievelijk ♀ of ♂) te kiezen, daarna komt de rest, de uit te spreken tekst.
De kappersklant wordt gestart met bin/kappersklant:
<<frog-will-run>> export MODEL=<<default-model>> <<pinteresque-pipeline>>
Elk onderdeel van de pipe-line ondersteunt het model als parameter. Vandaar dat de selector gestart kan worden met:
<<frog-will-run>> export MODEL=selector <<pinteresque-pipeline>>
<<frog-will-run>> [ "$DOSPKVOLUME" != "" ] && eval $DOSPKVOLUME export MODEL=ir-bot <<pinteresque-pipeline>>
rm -f /tmp/terminal; mkfifo /tmp/terminal [ "$MICCONTROLLER" = "" ] && MICCONTROLLER=0 [ "$MICNAME" = "" ] && MICNAME=Capture trap "amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap" 0 INT PIPE TERM amixer -c ${MICCONTROLLER} -q set ${MICNAME} nocap # newline in following is necessary, the whole system is line-buffered (tput -T linux clear; echo) > /tmp/terminal & while : do cat -u < /tmp/terminal | tee -a logs/terminal.txt | sed -u 's/^[vm] //' | fold -w 64 -s > /dev/tty0 sleep 1 # in a loop as the reading from terminal terminates upon write-close of other processes done & [ "$DOSPKVOLUME" != "" ] && eval $DOSPKVOLUME #amixer -c 1 sset Speaker 80%,80% [ ! -d logs ] && mkdir logs export MODEL=sorry bin/asr "${MODEL}" | bin/tea -k -o - -o /tmp/terminal | bin/nlu "${MODEL}" | \ ./pinteresque -b -m "${MODEL}" -v | \ bin/tea -k -o - -o /tmp/terminal -o logs/speechout.txt | bin/tts "${MODEL}" amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap
Merk op dat de selector op een Raspberry Pi draait en geen frog
kan starten vanwege geheugengebrek. De selector gebruikt de
frog-instance op htip.helberg.nl.▮
Frog moet draaien en is onafhankelijk van het gekozen model:
if [ "$RAMSIZE" -ge 4 ] then frogsrunning=`netstat -an | grep 8080 | wc -l` [ "$frogsrunning" = 0 ] && nohup frog -S 8080 >> frog.log 2>&1 & [ "$frogsrunning" = 0 ] && sleep 6 # wait for frog to settle in, takes a loong time fi
Om Pintereresque te kunnen draaien moeten enkele
environment-variabelen gezet zijn. Die staan in setenv en worden
in de top-scripts ge- sourced. Dat script is gebaseerd op
3.5.7.1.
Sourcen gebeurt middels:
# setenvplaceholder [ -r ~/setenv ] && . ~/setenv [ -r ./setenv ] && . ./setenv
3.5.1.1 System startup script
Om de gespreksbot automatisch te starten is een
systemd-configuratie nodig. Deze file komt terecht in
/etc/systemd/system/pinteresque.service.
[Unit] Description=Pinteresque, de gespreksbot Requires=network-online.target postgresql.service After=postgresql.service [Service] Type=simple User=pin WorkingDirectory=/home/pin/bot ExecStart=/home/pin/bot/bin/startpinteresque Restart=always [Install] WantedBy=multi-user.target
# setenvplaceholder [ -r ~/setenv ] && . ~/setenv [ -r ./setenv ] && . ./setenv bin/sidechannel 2>>log & [ "$THISBOT" = "sorry" ] && export MODEL=sorry [ "$THISBOT" = "selectionautomat" ] && export MODEL=ir-bot [ "$THISBOT" = "pinteresque" ] && export MODEL=kappersklant [ "$THISBOT" = "sorry" ] && bin/sorry [ "$THISBOT" = "selectionautomat" ] && bin/ir-bot [ "$THISBOT" = "pinteresque" ] && bin/ir-bot
3.5.1.1.1 Remote support
In order to facilitate remote diagnostics, we start a
autossh-command for remote login from the $WEBSERVER.
For this to work, ensure openssh and autossh are installed.
The systemd-file is:
[Unit] Description=Remote support for Pinteresque After=network.target [Service] Type=simple User=pin WorkingDirectory=/home/pin/bot ExecStart=/home/pin/bot/bin/startsupport Restart=always [Install] WantedBy=multi-user.target
The script opening up ssh on port 8022 on the webserver is:
# setenvplaceholder [ -r ~/setenv ] && . ~/setenv [ -r ./setenv ] && . ./setenv autossh -NR 8022:127.0.0.1:22 $WESBSERVER
Copy the systemd file into /etc/systemd/system/, type
systemctl enable startsupport and
systemctl start startsupport.
3.5.1.2 Installatievoorwaarden
Pinteresque gebruikt een PostgreSQL RDBMS voor opslag.
apt install postgresql echo "configure postgres-server to trust all incoming logons first"; read answ su -c "createdb pin" postgres su -c "createuser joost" postgres su -c "psql -h localhost -d pin -f create.ddl" pi su -c "psql -h localhost -d pin -f inserts.ddl" pi
apt install csvtool apt install gawk apt install rsync apt install net-tools apt install openssh apt install autossh
3.5.2 Rasa
Voor Rasa is enige installatie op het computersysteem nodig:
apt install python3-scipy apt install python3-openturns apt install libopenblas-dev apt install python3-ripe-atlas-sagan apt install python3-sklearn-lib python3-sklearn-pandas apt install python3-pip pip3 install rasa_nlu pip3 install rasa_nlu[spacy] python3 -m spacy download nl_core_news_sm python3 -m spacy download nl
We gebruiken de spacy pipe-line, dat is voor intent-lijsten van minder dan 1000 regels. Op een raspberry pi moet je rekening houden met 1 tot anderhalve Gb geheugengebruik, mogelijk is het dus noodzakelijk om swap toe te voegen.
Bedenk ook dat python3 nodig is, versie 2 functioneert
onvoldoende in combinatie met Rasa.
3.5.3 Frog
Frog analyseert NL-teksten en ontdekt getallen, data, eigennamen en talloze andere onderdelen van een zin.
Voor Frog is nodig
apt install frog frogdata
Pinteresque gebruikt Frog om te toetsen of een gegeven woord een werkwoord is of niet. Dat is nodig omdat Rasa denkt dat de persoon die zegt: “Hi, ik ben karel”, gewoon Ben heet.
Met Frog kunnen we nog heel veel meer natuurlijk, dat is voor later.
3.5.4 Kaldi, inclusief NL model
Installatie van de UT-versie van Kaldi is niet recht-toe-recht-aan.
git clone https://github.com/opensource-spraakherkenning-nl/Kaldi_NL.git git clone https://github.com/kaldi-asr/kaldi.git kaldi --origin upstream
en volg installatie-instructies (eerst in tools, daarna in
src).
Bedenk dat je ook mp3 support voor sox nodig hebt.
sox --help | grep 'FORMAT.*mp3' || apt install libsox-fmt-mp3
Het configure-script van Kaldi_NL stelt een aantal vragen, na
kiezen wordt een scherm getoond met de gemaakte keuzes. De
adviezen zoals gegeven in de README.md op github werden
opgevolgd. Na de bevestiging zoals getoond in figuur
3 wordt er enige uren gerekend (en geswapt,
ongeveer 40GB RAM en 7GB disk is de maximale working set).
Figuur 3: Kaldi-NL keuzes
Bovenstaand script zou een nieuw script moeten genereren:
decode.sh, dat gebeurt echter niet. Met de hand sloop ik de
graph-generation code uit configure.sh en dan wordt decode.sh wel
gemaakt. Een van de stappen in het genereren van de graphs faalt
waarschijnlijk.
decode.sh heeft een wav-file als argument, en een
output-directory voor tussenresultaten. Het script prepareert een
aantal bestanden voor gebruik door Kaldi. Zo ver komt het niet,
want een van de tussen-scripts (nl. spk2utt) is afwezig, de andere
tussen-scripts zijn 0 bytes groot.
Als we kaldi direct aanroepen met de juiste opties voor de modellen, dan faalt ie op input-formaat. Daar is vast wat aan te doen, maar vooralsnog snap ik er te weinig van.
Na een paar uur en veel swappen (op SSD :-()), roep ik aan als TCP-server op poort 5050: –config=~/work/Kaldi_NL/models/NL/UTwente/HMI/AM/CGN_all/nnet3_online/tdnn/v1.0/conf/online.conf –config ~/work/Kaldi_NL/models/NL/UTwente/HMI/AM/CGN_all/nnet3_online/tdnn/v1.0/conf/online.conf
~/work/kaldi/src/online2bin/online2-tcp-nnet3-decode-faster \ --samp-freq=8000 --frames-per-chunk=20 \ --extra-left-context-initial=0 --frame-subsampling-factor=3 \ --min-active=200 --max-active=7000 --beam=15.0 --lattice-beam=6.0 \ --acoustic-scale=1.0 --port-num=5050 \ ~/work/Kaldi_NL/models/NL/UTwente/HMI/AM/CGN_all/nnet3_online/tdnn/v1.0/final.mdl \ ~/work/Kaldi_NL/models/NL/UTwente/HMI/LM/KrantenTT/v1.0/LG_KrantenTT.4gpr.kn.int_UTwente_HMI_lexicon/G.fst \ ~/work/Kaldi_NL/models/NL/UTwente/HMI/LM/KrantenTT/v1.0/LG_KrantenTT.4gpr.kn.int_UTwente_HMI_lexicon/lang/words.txt
Een client kan dan met:
arecord -d5 -r 8000 -c 1 -f s16 -t raw -q - | nc -N localhost 5050
De WAV-audio naar kaldi sturen.
Helaas:
LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:RemoveOrphanNodes():nnet-nnet.cc:948) Removed 1 orphan nodes. LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:RemoveOrphanComponents():nnet-nnet.cc:847) Removing 2 orphan components. LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:Collapse():nnet-utils.cc:1378) Added 1 components, removed 2 LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:CompileLooped():nnet-compile-looped.cc:345) Spent 0.0102291 seconds in looped compilation. LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:Listen():online2-tcp-nnet3-decode-faster.cc:331) TcpServer: Listening on port: 5050 LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:Accept():online2-tcp-nnet3-decode-faster.cc:345) Waiting for client... LOG (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:Accept():online2-tcp-nnet3-decode-faster.cc:364) Accepted connection from: 127.0.0.1 ERROR (online2-tcp-nnet3-decode-faster[5.5.286~1-b96ca]:DecodableNnetLoopedOnlineBase():decodable-online-looped.cc:46) Input feature dimension mismatch: got 13 but network expects 40 [ Stack-Trace: ] kaldi::MessageLogger::LogMessage() const kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&) kaldi::nnet3::DecodableNnetLoopedOnlineBase::DecodableNnetLoopedOnlineBase(kaldi::nnet3::DecodableNnetSimpleLoopedInfo const&, kaldi::OnlineFeatureInterface*, kaldi::OnlineFeatureInterface*) main __libc_start_main _start
Een functionerende Kaldi kan ondergebracht worden in het script in figuur 20.
3.5.5 Modellen en teksten
Pinteresque levert een paar scripts voor het faciliteren van training en het verwerken van de gebruikers-input files (de modellen en de teksten).
Het model wordt bij het trainen opgepakt door de Rasa software. De door de bot uit te spreken (aka pintexts ) teksten worden naar een database gestuurd; de database die Pinteresque gebruikt voor het selecteren van teksten. De pintents komen ook in de database terecht, die kunnen worden gebruikt voor het verbeteren van de intent-matching.
Het formaat van de pintexts lijkt op die van de intents, alleen
wordt er aan de teksten een manier toegevoegd die de clue noemt
die met deze tekst aan de ander ontlokt wordt:
clue-to-induce. Dat gebeurt met ><clue-name>.
Het script (pintexts2db) bemonstert die database:
De parser van de pintexts-file is in AWK geschreven:
BEGIN {OFS=""; IFS="\n"; RS="##"; theintent=""; newpersona=0}; /intent:/ {split( $0, intents, ":" ); split( intents[ 2 ], fields, "+ " ); theintent=fields[ 1 ]; gsub( /[ \t\n]+$/,"", theintent ); for( i = 2; i <= length( fields ); i++) { gsub( /[ \t\n]+$/,"", fields[ i ] ); gsub( /^[ \t]+/,"", fields[ i ] ); thetype="!" if( index( fields[ i ], "?") ) { thetype="?" } split( fields[ i ], intentparts, ">") gsub(/[\n]+$/, intentparts[ 2 ] ) mod="" if( intentparts[ 1 ] ~ /^[*&@%~!=%]/ ) { mod = substr( intentparts[ 1 ], 1, 1 ) intentparts[ 1 ] = substr( intentparts[ 1 ], 2 ) } printf( "insert into texts (direction, type, intent, model, content, cluetoinduce, active, modifier) " ); printf( "values ($$out$$, $$%s$$, $$%s$$, $$%s$$, $$%s$$, $$%s$$, true, $$%s$$);\n", thetype, theintent, ENVIRON["model"], intentparts[ 1 ], intentparts[ 2 ], mod ); } } /clue:/ {split( $0, clues, ":" ); split( clues[ 2 ], fields, "\n" ); name=fields[ 1 ]; if( name == "naam" ) { if( newpersona == 0 ) { printf( "update persons set isrobot = false where model = $$%s$$ and isrobot;\n", ENVIRON["model"] ) } newpersona++ printf( "insert into persons ( model, isrobot ) values ( $$%s$$, true ) returning id as personaid\n\\gset\n", ENVIRON["model"] ) } value=""; priority=""; postags=""; for( i = 2; i <= length( fields ); i++ ) { pair[1]=substr( fields[ i ], 1, 1); pair[2]=substr( fields[ i ], 3 ); if( pair[ 1 ] == "p" ) { priority = pair[ 2 ]; } if( pair[ 1 ] == "v" ) { value = pair[ 2 ]; } if( pair[ 1 ] == "t" ) { postags = pair[ 2 ]; } } printf( "insert into clues ( person, name, value, priority, model, postags ) " ); printf( "values ( :personaid, $$%s$$, $$%s$$, %s, $$%s$$, $$%s$$ )\n", name, value, priority, ENVIRON["model"], postags ); printf( "on conflict ON constraint clues_un do \n" ); printf( "update set value = $$%s$$, priority = %s, postags = $$%s$$;\n", value, priority, postags ); } END {}
Het AWK-script gebruikt ## als record-separator. Daardoor wordt
elke intent-sectie apart behandeld. Daarna wordt het record in
tweeën gesplitst op de :, die voorafgaat aan de naam van de
intent en de pintexts. Dat tweede deel begint dan met de
intent-naam en daarachter de teksten met
+
er als seperator steeds tussen. Die seperator wordt met split
gebruikt om alles op te splitsen in fields. Het eerste veld
daarvan is de intent-naam, de rest (2..length) zijn de
pintexts.
Omdat persona's gerefereerd worden door de trail, wordt bij het
laden van een model, de oude verzameling persona's niet
weggegooid. Ze worden op inactief gezet door isrobot op false
te zetten. Merk op dat in het awk-script SQL voor de PostgreSQL
cli: psql wordt gegenereerd. De insert van de persona levert een
id op dat verderop gebruikt wordt voor het invoegen van de
clues-rows. De geretourneerde id heet personaid en wordt
middels \gset als psql-variabele gezet. Refereren van dergelijke
variabelen gebeurt met een :-symbool: :personaid in de
clue-inserts wordt dus vervangen door het id van de net gemaakte
persona.
De pintexts kennen ook een eigen syntax, ze kunnen beginnen met modifiers die aangeven of er sprake is van herhaalbaarheid, exclusiviteit en aanwijzen als starttekst, zie daarvoor 3.4.2.
De clues voor de personas staan ook in het model-bestand. De naam is de eerste clue voor een nieuwe persona, er kunnen dus meer personas worden gemaakt. Bij het laden van een nieuwe model, worden de oude persona's ge-deactiveerd en de nieuwe invgevoegd. ▮
Voor het onderbrengen van de pintents in de database doorlopen we een vergelijkbaar proces:
De parser van de pintents-file is ook in AWK geschreven:
BEGIN {OFS=""; IFS="\n"; RS="##"; theintent=""; personaid=0}; /intent:/ {split( $0, intents, ":" ); split( intents[ 2 ], fields, "- " ); theintent=fields[ 1 ]; gsub( /[ \t\n]+$/,"", theintent ); for( i = 2; i <= length( fields ); i++) { gsub( /[ \t\n]+$/,"", fields[ i ] ); gsub( /^[ \t]+/,"", fields[ i ] ); numclues=match( fields[ i ], /\([a-z]+\)/, clues ); if( numclues ) { gsub( /[\(\)]/, "", clues[0] ); } printf( "insert into texts (direction, intent, model, content, cluetoinduce, active) " ); printf( "values ($$in$$, $$%s$$, $$%s$$, $$%s$$, $$%s$$, true);\n", theintent, ENVIRON["model"], fields[ i ], clues[0] ); } } END {}
Met de bovenstaande AWK-scripts in de hand, is het eenvoudig om de
inserts uit te voeren. Voor testdoeleinden is er een -n optie
die de insert-statements uitprint. De -f vervangt het model, met
-i voegt regels toe13.
doinserts=no [ "$1" = "-f" ] && doinserts=replace [ "$1" = "-n" ] && doinserts=cat shift export model=<<default-model>> # push into environment for awk-code to use [ "$1" != "" ] && model="$1" [ ! -r "models/${model}/pintexts.md" ] && echo "No pintexts.md found in models/${model}/" [ ! -r "models/${model}/pintexts.md" ] && exit 1 awk ' <<processpintext>> ' "models/${model}/pintexts.md" > /tmp/inserts$$.dml [ "$doinserts" = "replace" ] && \ (echo "update texts set active = false where active and model = '${model}';"; \ cat /tmp/inserts$$.dml) | \ psql -d pin -h localhost [ "$doinserts" = "cat" ] && \ (echo "update texts set active = false where active and model = '${model}';"; cat /tmp/inserts$$.dml) awk ' <<processpintent>> ' "models/${model}/pintents.md" > /tmp/inserts$$.dml [ "$doinserts" = "cat" ] && \ (echo "update texts set active = false where model = '${model}' and direction = 'in';"; cat /tmp/inserts$$.dml) [ "$doinserts" = "replace" ] && \ (echo "update texts set active = false where model = '${model}' and direction = 'in';"; \ cat /tmp/inserts$$.dml) | \ psql -d pin -h localhost exit 0
3.5.5.1 Samenhang
Als de teksten van een model worden vernieuwd, dan moeten er pintents en pintexten worden gemaakt, opnieuw worden getraind en moet de database vernieuwd worden. Elk script zal dat oplossen alvorens aan het echte werk te gaan.
<<source-setenv>> model=<<default-model>> [ "$1" != "" ] && model="$1" modelfile="${model}".md [ ! -r "${modelfile}" ] && modelfile="models/${modelfile}" [ ! -r "${modelfile}" ] && echo "No model found: ${model}.md or ${modelfile}" [ ! -r "${modelfile}" ] && exit 1 [ ! -d "models/${model}/" ] && mkdir -p "models/${model}/" cat "${modelfile}" | <<sed-cont>> | egrep '^## intent: ^<<pintent-sign>> ^$' | grep -v '^;' > "models/${model}/pintents.md" cat "${modelfile}" | <<sed-cont>> | egrep '^## intent: ^## clue: ^\<<pintext-sign>> ^<<clue-sign>> ^$' | grep -v '^;' > "models/${model}/pintexts.md" if true || grep :ipaddress "${modelfile}" > /dev/null then # ip address stuff is already in model echo "" else # add ip address stuff to model echo ' ## intent:ipaddress - wat is je ip - wat is je netwerkadres - wat is je ip adres ' >> "models/${model}/pintents.md" echo ' ## clue:ipaddress p 100 v placeholder ## intent:ipaddress + (me.ipaddress) ' >> "models/${model}/pintexts.md" fi bin/pintrain "${model}" >> log 2>&1 bin/pintexts2db -f "${model}" >> log 2>&1 exit 0
Merk op dat egrep gebruikt wordt om de intent-naam en de
enerzijds met - gemarkeerde intents te matchen en anderszijds de
met + gemarkeerde pintexts. Net als fgrep kan egrep meerdere
matches met elkaar OR-en door ze op verschillende regels te
noemen.
Voor het gebruik van pintext-sign in het shell-script staat een
\. Die is nodig zolang het pintext-teken een betekenis heeft in
reguliere expressies anders dan zichzelf.
Merk ook op dat het toevoegen van ip-adres-intents weggenomen is
(de if true || ...). Het leidt nl. tot false-positives die niet
alleen raar klinken (midden in je gesprek leest de bot een
ip-adres voor), maar ook andere reacties van de bot in de weg
staan. Als je het ip-adres wil weten, dan gebruik je de webserver
die een remotesupport-verbinding toestaat. ▮
Bij het genereren van de aparte pintents en pintexts, wordt ook
de continuation van lange regels opgelost met een
sed-commando. Omdat het patroon dat we willen
vervangen over meerdere regels verspreid is, gebruiken we een
label (a) en de N om de volgende regel toe te voegen aan de
pattern-space. Dat gebeurt tot de laatste regel $! en dan
wordt er vervangen.
sed ':a;N;$!ba;s/\<<cont-char>>\n[ ]*/ /g'
Zie ook de discussie op
stackoverflow.com:
how can i replace a newline using sed, mogelijk is sed -z 's/\n/ /g' ook
een goed idee.
▮
3.5.5.2 Afhankelijkheden
Pinteresque functioneert alleen goed indien de pintents samenhangen met de pintexts. Daarnaast moeten de Clues zoals genoemd in de pintents en gebruikt in de pintexts, aanwezig zijn binnen de applicatie.
Mbt Clues is het mogelijk om een nieuwe clue (geïntroduceerd door het noemen ervan in de pintents en het uitspreken ervan door een van de gebruikers) automatisch wordt bewaard en ook wordt toegevoegd aan het clue-apparaat van de personas en nieuwe personen.
De beheerder van Pinteresque zou dan eeb bericht kunnen ontvangen over de nieuwe Clue inclusief suggesties over de waardes voor de personas onder beheer.
In ieder geval is er behoefte aan een manier om te verifieren wat er mist op basis van wat de pintents en pintexts doen.
3.5.5.2.1 Ontbrekende Clues
Clues worden gematcht in de PIntents en de PIntexts en vervolgens gezocht in de database.
De volgende intents worden gebruikt in PIntexts en zijn beschikbaar in de PINtents:
echo $x | tr ' ' '\n' > /tmp/xs echo $i | tr ' ' '\n' > /tmp/is echo "in-PIntents|in-PIntexts|aanwezig" echo "niet-in-PIntexts|niet-in-PIntents|in-beide" echo "---------------- --------------- ---------------" diff -t -i -w -a \ --old-line-format='%L' \ --new-line-format='|%L' \ --unchanged-line-format='||%L' \ /tmp/is /tmp/xs exit 0
3.5.5.2.2 Intents
Ontbrekende PIntexts zijn lastig, dat houdt in dat een intent herkend wordt door de NLU, maar waar vervolgens niet op gereageerd kan worden.
Ontbrekende PIntents zijn minder ernstig, elke genoemde intent zal niet door de intent-analyzer worden herkend en zal dus nooit aankomen in Pinteresque. Daardoor zullen de teksten die onder deze Pintexten vallen nooit worden uitgesproken.
Optimaal is natuurlijk dat alle intents in beide bestanden aanwezig zijn.
echo $x | tr ' ' '\n' > /tmp/xs echo $i | tr ' ' '\n' > /tmp/is echo "in-PIntents|in-PIntexts|aanwezig" echo "niet-in-PIntexts|niet-in-PIntents|in-beide" echo "---------------- --------------- ---------------" diff -t -i -w -a \ --old-line-format='%L' \ --new-line-format='|%L' \ --unchanged-line-format='||%L' \ /tmp/is /tmp/xs exit 0
Een andere test kan achterhalen welke intents er ontbreken (de met <
ontbreken in de database, de met > gemarkeerde ontbreken in het
model):
| < | groet |
| < | naam |
| < | knippen |
| < | knippenoordekking |
| < | knippenlengte |
| < | knipopdrachtbevestiging |
| < | kappersprodukten |
| < | reistijd |
| < | hobby |
| < | sport |
| < | verkeer |
| < | leeftijd |
| < | pinty-internal |
| < | de-weg-kwijt |
3.5.6 Trainen
We gebruiken mogelijk meerdere modellen voor de gesprekken, het model
van de kappersklant en dat van de kapper zelf, maar ook andere
gesprekken kunnen worden vormgegeven. Vandaar dat het
model als parameter aan nlu-pipe wordt meegegeven.
En dan moet er natuurlijk een model opgesteld worden, met
configuratie-files voor de intent-analyse. Trainen van de
kappersklant gebeurt dan met het script bin/pintrain:
model=kappersklant [ "$1" != "" ] && model="$1" [ ! -r "models/${model}/pintents.md" ] && echo "No pintents.md found in models/${model}/" [ ! -r "models/${model}/pintents.md" ] && exit 1 python3 -m rasa_nlu.train -c nlu_config.yml --data "models/${model}/pintents.md" \ -o models --fixed_model_name "${model}" --project "" --verbose
3.5.6.1 Namen van jongens en meisjes
Indien Pinteresque vermoed dat er sprake is van een naam-intent, dat wordt er extra mooite gedaan om de clue die ‘naam’ heet op te lossen. Daarbij wordt gebruik gemaakt van informatie over wat eigennamen zijn. Voorlopig beperken we ons tot voornamen.
Voor de lijst van jongens- en meisjesnamen wordt onder meer die van Meertens gebruikt. Die staat op http://www.meertens.knaw.nl/nvb/downloads/Top_eerste_voornamen_NL_2010.zip en pakt uit tot een CSV-bestand.
pinnames converteert die naar lijsten voor gebruik door NLU en
inserts in de database voor gebruik door Pinteresque.
Achtereenvolgens wordt van de CSV de juiste kolom geselecteerd (2
voor vrouwen en 4 voor mannen), de hoofdletters naar kleine
letters vertaalt, de lege regels weggegooid en de eerste
header-regels weggehaald. Omdat de CSV in de letterset ISO-8859-1
gemaakt is, wordt er naar UTF-8 geconverteerd.
De beide tekstbestanden die dit oplevert (m.txt en v.txt)
worden door de intent-modellen gebruikt, maar ook door dit
script dat ze met psql in de database zet.
csvtool -t ';' col 2 Top_eerste_voornamen_NL_2010.csv | \ sed '/^$/d' | tail -n +3 | \ iconv -f 8859_1 -t utf-8//TRANSLIT > v.txt csvtool -t ';' col 4 Top_eerste_voornamen_NL_2010.csv | \ sed '/^$/d' | tail -n +3 | \ iconv -f 8859_1 -t utf-8//TRANSLIT > m.txt [ ! -s v.txt ] && exit 1 [ ! -s m.txt ] && exit 1 psql -d pin -h localhost -c 'copy names (name) from STDIN with csv' < m.txt psql -d pin -h localhost -c "update names set sex = 'm' where sex is null" psql -d pin -h localhost -c 'copy names (name) from STDIN with csv' < v.txt psql -d pin -h localhost -c "update names set sex = 'v' where sex is null" psql -d pin -h localhost -c "update names set name = lower(name)" rm -f v.txt m.txt
Deze Meertens lijst is echter waanzinnig beperkt en voor moderne toepassingen onvoldoende bruikbaar.
Het wordt aangevuld met de pagina's op:
Naamkunde
10.000 jongensnamen en
Naamkunde
10.000 meisjesnamen. Helaas staan daar geen CSV's en wordt het
screenscrapen. Die pagina's zijn onder respectievelijk m.html en
v.html bewaard. Die 10.000 wordt overigens overdreven, het gaat
om in totaal net geen 10.000 namen (om precies te zijn
\(4412 + 5343 = 9755\)).
for gender in m v do grep '(.)</td>' naamkunde/${gender}.html | \ sed 's/^[[:space:]]*<td>//' | sed 's%[[:space:]]*(.)</td>%%' > ${gender}.txt [ ! -s ${gender}.txt ] && exit -1 psql -d pin -h localhost -c 'copy names (name) from STDIN with csv' < ${gender}.txt psql -d pin -h localhost -c "update names set sex = '${gender}' where sex is null" rm -f ${gender}.txt done psql -d pin -h localhost -c "update names set name = lower(name)"
Als gevolg van de lower(name) zal misschien een aantal namen
opelkaar gemapt worden. Daarnaast zal de ene set veel doublures
vertonen met de andere set.
delete from names a using names b where a.id < b.id and a.name = b.name and a.sex = b.sex
| DELETE 2636 |
Er blijven dan bijna 10000 namen over.
select count(*) from names
| count |
|---|
| 9790 |
Enkele namen (zo'n 400) zijn niet genderspecifiek. Een tiental daarvan:
select name, count(*) from names group by name having count(*) > 1 order by random() limit 10
| name | count |
|---|---|
| imre | 2 |
| sultan | 2 |
| jay | 2 |
| misha | 2 |
| rinke | 2 |
| noé | 2 |
| luke | 2 |
| casey | 2 |
| jaden | 2 |
| yi | 2 |
3.5.7 Development
Zet GOPATH op de directory boven src (de top-dir van de repo).
3.5.7.1 Environment variables
Gebruik een setenv-file op basis van setenv.example.
3.5.7.2 Building
Voor build:
<<source-setenv>> make pinteresque livecaption texttospeech pin-sidechannel
Voor cross-compiling naar Raspberry Pi:
<<source-setenv>> make
Install on arm computer
<<source-setenv>> make make installremote #cat ir-bot.md | grep -v intent:begin | grep -v '+ @' > ir-prs.md
Install on amd64 computer, same architecture as my laptop
for cmd in pinteresque livecaption texttospeech pin-sidechannel do rsync ${cmd} pin@$ipad:bot/${cmd} done for cmd in nlu-pipe.py do rsync ${cmd} pin@$ipad:bot/${cmd} done for cmd in bin/{anno,asr,nlu,pinnames,pintexts2db,pintrain,renew,ir-bot,selector,sidechannel,tts,preport,startpinteresque} setenv.example do rsync ${cmd} pin@$ipad:bot/${cmd} done cat ir-bot.md | grep -v intent:begin | grep -v '+ @' > ir-prs.md for model in ir-bot.md ir-prs.md selector.md preport.in.txt do [ -r ${model} ] && rsync ${model} pin@$ipad:bot/${model} done for other in selomat.png preport.in.txt preport-all.in.txt webreport.in.html nlu_config.yml do [ -r ${other} ] && rsync ${other} pin@$ipad:bot/${other} done
3.5.8 Audio en rumoer
Tijdens het omkeerevent op 18 juni 2019 werkte de selection
automat eigenlijk vrij goed. Althans, totdat het druk werd en de
TTS geen pauzes meer kon onderscheiden in de spraak van de
persoon. Dat kwam door het luide rumoer op de achtergrond. De
selection automat, met Raspberry Pi en 2-mic Seeed audio hat en
een telefoonhoorn kon voorgrond niet meer van achtergrond scheiden
en stuurde uiteindelijk pas steeds na 60 seconden tekst naar
NLU. Veel van de tekst was vervolgens ook nog eens onterecht uit
het rumoer opgepikt.
Omdat we in de selection automat opzet drie microfoons gebruiken, waarvan er eentje dicht bij de spreker zit, zou echo cancellation goed uit te voeren moeten zijn. Het idee is dat elke microfoon geluid oppikt en dat de anti-echo-software verteld wordt wat de afstanden zijn tussen die drie microfoons en de belangrijkste spreker. De software kan vervolgens het geluid dat de microfoons ver weg oppikken corrigeren en afhalen van het geluid dat door het dichtbij-exemplaar wordt opgepikt. Daarmee zou het geroezemoes verdwijnen en de bedoelde stem overblijven.
In Voice-engine: ec wordt
uitgelegd hoe een en ander kan worden ingericht, maar die is
expliciet voor het wegfilteren van de zelf geproduceerde
audio. Daar waar het script bin/tts de microfoon steeds uit en
aan zet, zou deze oplossing de microfoon altijd aan kunnen laten.
Als de ruis steeds hetzelfde is, dan kan Filtering out noise gebruikt worden. Dat is echter niet in het geval van de selection automat. In Real-Time background noise… wordt hetzelfde gedaan, maar dan met regelmaat. Dan is het net alsof het noise-profile altijd up-to-date is.
Pulseaudio heeft een oplossing voor noise en echo cancellation, maar vooralsnog gebruiken we pulse niet.
3.5.8.1 De 2-mic Seeed Pi hat
Het commando amixer -c 1 op een Pi (met de Seeed op controller 1) levert:
Simple mixer control 'Headphone',0 Capabilities: pvolume Playback channels: Front Left - Front Right Limits: Playback 0 - 127 Mono: Front Left: Playback 127 [100%] [6.00dB] Front Right: Playback 127 [100%] [6.00dB] Simple mixer control 'Headphone Playback ZC',0 Capabilities: pswitch Playback channels: Front Left - Front Right Mono: Front Left: Playback [off] Front Right: Playback [off] Simple mixer control 'Speaker',0 Capabilities: pvolume Playback channels: Front Left - Front Right Limits: Playback 0 - 127 Mono: Front Left: Playback 112 [88%] [-9.00dB] Front Right: Playback 111 [87%] [-10.00dB] Simple mixer control 'Speaker AC',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 5 Mono: 2 [40%] Simple mixer control 'Speaker DC',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 5 Mono: 2 [40%] Simple mixer control 'Speaker Playback ZC',0 Capabilities: pswitch Playback channels: Front Left - Front Right Mono: Front Left: Playback [off] Front Right: Playback [off] Simple mixer control 'PCM Playback -6dB',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Mono Output Mixer Left',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Mono Output Mixer Right',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Playback',0 Capabilities: volume Playback channels: Front Left - Front Right Capture channels: Front Left - Front Right Limits: 0 - 255 Front Left: 255 [100%] [0.00dB] Front Right: 255 [100%] [0.00dB] Simple mixer control 'Capture',0 Capabilities: cvolume cswitch Capture channels: Front Left - Front Right Limits: Capture 0 - 63 Front Left: Capture 39 [62%] [12.00dB] [on] Front Right: Capture 39 [62%] [12.00dB] [on] Simple mixer control '3D',0 Capabilities: volume volume-joined pswitch pswitch-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 15 Mono: 0 [0%] Playback [off] Simple mixer control '3D Filter Lower Cut-Off',0 Capabilities: enum Items: 'Low' 'High' Item0: 'Low' Simple mixer control '3D Filter Upper Cut-Off',0 Capabilities: enum Items: 'High' 'Low' Item0: 'High' Simple mixer control 'ADC Data Output Select',0 Capabilities: enum Items: 'Left Data = Left ADC; Right Data = Right ADC' 'Left Data = Left ADC; Right Data = Left ADC' 'Left Data = Right ADC; Right Data = Right ADC' 'Left Data = Right ADC; Right Data = Left ADC' Item0: 'Left Data = Left ADC; Right Data = Right ADC' Simple mixer control 'ADC High Pass Filter',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'ADC PCM',0 Capabilities: cvolume Capture channels: Front Left - Front Right Limits: Capture 0 - 255 Front Left: Capture 195 [76%] [0.00dB] Front Right: Capture 195 [76%] [0.00dB] Simple mixer control 'ADC Polarity',0 Capabilities: enum Items: 'No Inversion' 'Left Inverted' 'Right Inverted' 'Stereo Inversion' Item0: 'No Inversion' Simple mixer control 'ALC Attack',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 15 Mono: 2 [13%] Simple mixer control 'ALC Decay',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 15 Mono: 3 [20%] Simple mixer control 'ALC Function',0 Capabilities: enum Items: 'Off' 'Right' 'Left' 'Stereo' Item0: 'Off' Simple mixer control 'ALC Hold Time',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 15 Mono: 0 [0%] Simple mixer control 'ALC Max Gain',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 7 [100%] Simple mixer control 'ALC Min Gain',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] Simple mixer control 'ALC Mode',0 Capabilities: enum Items: 'ALC' 'Limiter' Item0: 'ALC' Simple mixer control 'ALC Target',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 15 Mono: 4 [27%] Simple mixer control 'DAC Deemphasis',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'DAC Mono Mix',0 Capabilities: enum Items: 'Stereo' 'Mono' Item0: 'Stereo' Simple mixer control 'DAC Polarity',0 Capabilities: enum Items: 'No Inversion' 'Left Inverted' 'Right Inverted' 'Stereo Inversion' Item0: 'No Inversion' Simple mixer control 'Left Boost Mixer LINPUT1',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Left Boost Mixer LINPUT2',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Left Boost Mixer LINPUT3',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Left Input Boost Mixer LINPUT1',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 3 Mono: 3 [100%] [29.00dB] Simple mixer control 'Left Input Boost Mixer LINPUT2',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-99999.99dB] Simple mixer control 'Left Input Boost Mixer LINPUT3',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-99999.99dB] Simple mixer control 'Left Input Mixer Boost',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Left Output Mixer Boost Bypass',0 Capabilities: volume volume-joined pswitch pswitch-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-21.00dB] Playback [off] Simple mixer control 'Left Output Mixer LINPUT3',0 Capabilities: volume volume-joined pswitch pswitch-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-21.00dB] Playback [off] Simple mixer control 'Left Output Mixer PCM',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Noise Gate',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Noise Gate Threshold',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 31 Mono: 0 [0%] Simple mixer control 'Right Boost Mixer RINPUT1',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Right Boost Mixer RINPUT2',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Right Boost Mixer RINPUT3',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [off] Simple mixer control 'Right Input Boost Mixer RINPUT1',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 3 Mono: 3 [100%] [29.00dB] Simple mixer control 'Right Input Boost Mixer RINPUT2',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-99999.99dB] Simple mixer control 'Right Input Boost Mixer RINPUT3',0 Capabilities: volume volume-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 0 [0%] [-99999.99dB] Simple mixer control 'Right Input Mixer Boost',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Right Output Mixer Boost Bypass',0 Capabilities: volume volume-joined pswitch pswitch-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 5 [71%] [-6.00dB] Playback [off] Simple mixer control 'Right Output Mixer PCM',0 Capabilities: pswitch pswitch-joined Playback channels: Mono Mono: Playback [on] Simple mixer control 'Right Output Mixer RINPUT3',0 Capabilities: volume volume-joined pswitch pswitch-joined Playback channels: Mono Capture channels: Mono Limits: 0 - 7 Mono: 2 [29%] [-15.00dB] Playback [off]
3.6 Rapportage
De gespreksbot slaat alle gesprekken op, inclusief enkele andere attributen die horen bij de conversatie.
Er zijn twee vormen van rapportage; die aan de gesprekspartner en die aan de applicatiebeheerder.
3.6.1 Een oordeel
Sommige gesprekken vellen een oordeel. Dat komt dan uit een aangesloten printer, voor de gesprekspartner om af te scheuren en mee te nemen.
De inhoud van het rapport (klein landscape etiket) bestaat uit de voornaam en wat titels met waardes. De etiket-keuze (links of rechts) is onderdeel van de rapportage vanwege de samenhang tussen oordeel en kleur.
De metrics zijn:
- voornaam
- leeftijd
- aantal gewenste competentie-matches (intents met positieve
waardering):
P: <aantal> - aantal ongewenste competentie-matches (intents met negatieve
waardering):
N: <aantal> verhouding intrinsiek/extrensiek woordgebruik:
R: <ratio>, berekend als \(N_i / N_e\) en met twee cijfers achter de komma. \(N_i\) wordt berekend door het aantal malen tellen van:('ik', 'mij', 'zelf', 'mezelf', 'mijn')
\(N_e\) gaat dan om tellen van:
('wij', 'zij', 'hen', 'hun', 'hij', 'zij', 'hullie','haar','zijn','zullie')
Een grote R betekent veel intrinsiek taalgebruik, een kleine (kleiner dan 1.0) betekent veel extrensiek taalgebruik. In een soll. gesprek zal een goede ratio tussen de 1 en de 3 liggen.
noemen van het meest gebruikte woord met een lengte van meer dan:
3
Dit is een manier om stopwoorden te rapporteren.
Het al of niet doorgaan voor een volgend gesprek hangt dan af van:
((p >= n OR (p = 0 AND n = 0)) AND h < 6 AND r < 5 AND coalesce( leeftijd::int, 43 ) < 44) OR (extract( second from CURRENT_TIME)::int % 3 = 0)
Er wordt alleen gerapporteerd indien een gesprek een audit-trail heeft met een lengte van minimaal:
10
Er wordt alleen gerapporteerd indien het gesprek beëindigd werd. Dat wordt door het ophangen van de hoorn veroorzaakt. Zie de 3.3.5 voor de SQL die vervolgens over welke persoon wat wordt gerapporteerd.
3.6.1.1 Het rapport voor op de printer
Het persoonlijke rapport drukt die van het meest recente gesprek af. Het template ervoor:
@sqlwith
theperson as (
select p.id, p.model
from trail t JOIN persons p ON t.person = p.id
where ( not p.endtime is null
and p.endtime > (CURRENT_TIMESTAMP - interval '20 second'))
or p.id = @param<pid>
group by p.id, p.endtime, p.model
having count(t.*) > 4
order by p.endtime DESC limit 1
),
thetrail as (
select p.id, max(pit) as pit,
to_char( max(pit) - min(pit), 'mi:ss' ) as duration,
(select coalesce( value, '<tbd>')
from clues
where person = p.id and name = 'naam') as naam,
(select coalesce( value, '30')
from clues
where person = p.id and name = 'leeftijd') as leeftijd,
(select coalesce( value, '<tbd>')
from clues
where person = t.persona and name = 'naam' and model = p.model) as persona,
count(intentname) filter (where intentname like '%pos%') as p,
count(intentname) filter (where intentname like '%neg%') as n,
count(intentname) filter (where intentname like '%herhalen%') as h,
string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) as tt
from trail t JOIN theperson p ON p.id = t.person
group by p.id, t.persona, p.model
having length( string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) ) > 10
order by max(pit) DESC limit 20
),
themetrics as (
select thetrail.persona,
thetrail.naam,
thetrail.leeftijd,
thetrail.duration,
thetrail.id,
to_char( thetrail.pit, 'HH24:MI') as tm,
1.0*(select count(*) + 1
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where d in ('ik', 'mij', 'zelf', 'mezelf', 'mijn'))
/
(select count(*) + 1
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where d in ('wij', 'zij', 'hen', 'hun', 'hij', 'zij', 'hullie','haar','zijn','zullie'))
as R,
p, n, h,
(select '"'||words.d||'" '||count(*)||' keer' as stopword
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where length(d) > 3
group by d
order by count(*) DESC limit 1) as stopwoord
from thetrail
)
select case when ((p >= n OR (p = 0 AND n = 0)) AND h < 6 AND r < 5 AND coalesce( leeftijd::int, 43 ) < 44) OR (extract( second from CURRENT_TIME)::int % 3 = 0)
then 'Door naar volgende gesprek'
else 'Twijfel, interventie nodig'
end as through,
duration,
tm, id,
persona, naam, leeftijd, to_char( r, '00.99' ) as r, p, n, h, stopwoord
from themetrics;
Stts: @field<through>
Tijd: @field<tm>; Duur: @field<duration>; Interviewer: @field<persona>
Naam: @field<naam>; Leeftijd: @field<leeftijd>; Pid: @field<id>
Kengetallen: r: @field<r>, p: @field<p>, n: @field<n>, h: @field<h>
Stopwoord: @field<stopwoord>
@sqlend
De versie voor intern gebruik met alle uitslagen van de afgelopen twee dagen:
@sqlwith
theperson as (
select p.id, p.model
from trail t JOIN persons p ON t.person = p.id
where not p.endtime is null
and p.endtime > (CURRENT_TIMESTAMP - interval '2 day')
group by p.id, p.endtime, p.model
having count(t.*) > 4
order by p.endtime DESC
),
thetrail as (
select p.id, max(pit) as pit,
to_char( max(pit) - min(pit), 'mi:ss' ) as duration,
(select coalesce( value, '<tbd>')
from clues
where person = p.id and name = 'naam') as naam,
(select coalesce( value, '30')
from clues
where person = p.id and name = 'leeftijd') as leeftijd,
(select coalesce( value, '<tbd>')
from clues
where person = t.persona and name = 'naam' and model = p.model) as persona,
count(intentname) filter (where intentname like '%pos%') as p,
count(intentname) filter (where intentname like '%neg%') as n,
count(intentname) filter (where intentname like '%herhalen%') as h,
string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) as tt
from trail t JOIN theperson p ON p.id = t.person
group by p.id, t.persona, p.model
having length( string_agg( rtrim((t.intent->>'text'),E'\n'), ' ' ) ) > 10
order by max(pit) DESC limit 20
),
themetrics as (
select thetrail.persona,
thetrail.naam,
thetrail.leeftijd,
thetrail.duration,
thetrail.id,
to_char( thetrail.pit, 'HH24:MI') as tm,
1.0*(select count(*) + 1
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where d in ('ik', 'mij', 'zelf', 'mezelf', 'mijn'))
/
(select count(*) + 1
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where d in ('wij', 'zij', 'hen', 'hun', 'hij', 'zij', 'hullie','haar','zijn','zullie'))
as R,
p, n, h,
(select '"'||words.d||'" '||count(*)||' keer' as stopword
from regexp_split_to_table( thetrail.tt, '\s+' ) as words(d)
where length(d) > 3
group by d
order by count(*) DESC limit 1) as stopwoord
from thetrail
)
select case when ((p >= n OR (p = 0 AND n = 0)) AND h < 6 AND r < 5 AND coalesce( leeftijd::int, 43 ) < 44) OR (extract( second from CURRENT_TIME)::int % 3 = 0)
then 'Ja'
else 'Twijfel, interventie nodig'
end as through,
duration,
tm, id,
persona, naam, leeftijd, to_char( r, '00.99' ) as r, p, n, h, stopwoord
from themetrics
order by id DESC;
Door: @field<through>
Tijd: @field<tm>; Duur: @field<duration>; Interviewer: @field<persona>
Naam: @field<naam>; Leeftijd: @field<leeftijd>; Pid: @field<id>
Kengetallen: r: @field<r>, p: @field<p>, n: @field<n>, h: @field<h>
Stopwoord: @field<stopwoord>
@sqlend
Het script dat het juiste etiket afdrukt:
bin/todisplay "Reporting" & sleep 2 # wait for Pinteresque to end the current person bin/reduce -u postgres://localhost/pin -i preport.in.txt -o out.txt pid:0 bin/reduce -u postgres://localhost/pin -i webreport.in.html -o out.html pid:0 numl=`wc -l out.txt | awk '{print $1}'` if [ "$numl" -lt 3 ] then echo "Empty report, not generating one." >> log echo "v Te kort gesprek, geen rapport." | bin/tts bin/todisplay "Interview too short" & sleep 1 bin/todisplay "Pick up to start" & exit 1 fi SLOT=Left grep "Stts: Door" out.txt > /dev/null && SLOT=Right convert selomat.png -gravity west -size 630x220 caption:@out.txt -composite out.png convert -rotate 90 out.png etiket.png cat etiket.png | lp -o InputSlot=${SLOT} personid=`grep '<title>' out.html | sed 's/.*id: //' | sed 's/,.*//'` fn="`date +%T | sed 's/://g'`-$personid.html" mv out.html "$fn" numl=`wc -l "$fn" | awk '{print $1}'` if [ "$numl" -lt 8 ] then echo "Empty webreport, not generating one." >> log exit 0 fi scp "$fn" $WEBSERVER:/var/www/htip/pin/webreports/ && mv "$fn" reports/ bin/todisplay "Pick up to start" &
Voor de sorrybot, het script dat een excuus maakt en publiceert:
[ "$MICCONTROLLER" = "" ] && MICCONTROLLER=0 [ "$MICNAME" = "" ] && MICNAME=Capture trap "amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap" 0 INT PIPE TERM amixer -c ${MICCONTROLLER} -q set ${MICNAME} nocap bin/reduce -u postgres://localhost/pin -i excuse.in.html -o excuus-$1-$2.html pid:$1 pida:$2 scp excuus-$1-$2.html $WEBSERVER:/var/www/htip/pin/excuses/nieuwste.html scp excuus-$1-$2.html $WEBSERVER:/var/www/htip/pin/excuses/reports/ && mv "excuus-$1-$2.html" reports/
[ "$MICCONTROLLER" = "" ] && MICCONTROLLER=0 [ "$MICNAME" = "" ] && MICNAME=Capture trap "amixer -c ${MICCONTROLLER} -q set ${MICNAME} cap" 0 INT PIPE TERM amixer -c ${MICCONTROLLER} -q set ${MICNAME} nocap
3.6.2 Verbetering
Rapportage over gesprekken is een belangrijk middel voor het interpreteren van de kwaliteit van de dialogen, de code en het model.
3.6.3 Gesprekken
Na elk gesprek wordt er een uitgebreid rapport naar ene centrale web-server gecopieerd. Dat rapport wordt gebruikt voor het verbeteren van het model en de software. Het kent geen parameter, maar zal over de meest recente persoon (mits kortgeleden) rapporteren.
<html> @sqlwith theperson as ( select p.id, p.model from trail t JOIN persons p ON t.person = p.id where ( not p.endtime is null and p.endtime > (CURRENT_TIMESTAMP - interval '20 second')) or p.id = @param<pid> group by p.id, p.endtime, p.model having count(t.*) > 4 order by p.endtime DESC limit 1 ) select id as personid, model from theperson; <head> <meta charset="UTF-8"> <title>id: @field<personid>, @field<model></title> </head> <body> <H1>Intents en gematchte Clues</H1> <table> <tr><td>tijdstip</td><td>intent</td><td>confidence</td><td>clue: waarde</td></tr> @sqlselect to_char( pit, 'HH24:MI:SS') as tijdstip, ((intent->>'intent')::jsonb)->>'name' as name, to_char( (((intent->>'intent')::jsonb)->>'confidence')::float, '0.99' ) as conf, ((intent->>'entities')::jsonb)->0->>'entity'||': '||(((intent->>'entities')::jsonb)->0->>'value') as slot from trail where person = @field<personid> order by pit; <tr><td>@field<tijdstip></td><td>@field<name></td><td>@field<conf></td><td>@field<slot></td></tr> @sqlend </table> <H1>Gesprek</H1> @sqlwith rep as ( select id, to_char(t.pit, 'HH24:MI:SS' ) as tijdstip, 'prsn: ' as speaker, rtrim((t.intent->>'text'),E'\n') as tekst, 1 as rank from trail t where person = @field<personid> UNION select id, to_char(t.pit, 'HH24:MI:SS' ) as tijdstip, 'bot : ' as speaker, t.output as tekst, 2 as rank from trail t where person = @field<personid> order by id, tijdstip, rank ) select tijdstip, speaker, tekst from rep; <p><b>@field<tijdstip></b> <i>@field<speaker></i>@field<tekst> </p> @sqlend <H1>Clues</H1> <table> <tr><td>naam</td><td>waarde</td></tr> @sqlselect person, name, value from clues where person = @field<personid> order by id; <tr><td>@field<name></td><td>@field<value></td></tr> @sqlend </table> </body> @sqlend </html>
Excuusrapport heeft als parameter pid, de id van de person.
<html> <head> <meta http-equiv="refresh" content="5" /> <meta charset="UTF-8"> @sqlselect coalesce( initcap( naam.value ), 'onbekende' ) as naam, coalesce( waarvoor.value, 'iets waarvan ik niets weet' ) as waarvoor, coalesce( gevoel.value, 'teleurgesteld' ) as gevoel, coalesce( initcap( wie.value ), 'de onbekende' ) as wie, coalesce( waarom.value, 'het niet meezat' ) as waarom, coalesce( anders.value, 'beter kunnen doen' ) as anders, coalesce( rol.value, 'niet geinteresseerd' ) as rol, (select initcap( value ) from clues where person = @param<pida> and name = 'naam') as botnaam from persons p LEFT OUTER JOIN clues naam ON naam.person = p.id and naam.name = 'naam' LEFT OUTER JOIN clues waarvoor ON waarvoor.person = p.id and waarvoor.name = 'waarvoor' LEFT OUTER JOIN clues gevoel ON gevoel.person = p.id and gevoel.name = 'gevoel' LEFT OUTER JOIN clues wie ON wie.person = p.id and wie.name = 'wie' LEFT OUTER JOIN clues anders ON anders.person = p.id and anders.name = 'anders' LEFT OUTER JOIN clues waarom ON waarom.person = p.id and waarom.name = 'waarom' LEFT OUTER JOIN clues rol ON rol.person = p.id and rol.name = 'rol' where p.id = @param<pid>; <title>Excuus voor @field<naam> mbt @field<waarvoor> (@param<pid>, @param<pida>)</title> <style type="text/css"> p { font-size: 3vw; margin-top: 0; margin-bottom: .3ex; } </style> </head> <body> <h1></h1> <p> Lieve @field<naam>. </p> <p> Wat fijn dat je hier bent. Ik wil graag mijn excuses aanbieden voor @field<waarvoor>. Nu pas besef ik wat dit met jou deed. En het is tijd dat ik daar mijn verantwoordelijkheid voor neem. </p> <p> Ik kan me voorstellen dat jij je toen @field<gevoel> voelde. En het spijt me dat ik jou dat gevoel heb gegeven. Dat was niet mijn bedoeling. </p> <p> Je kunt je misschien voorstellen dat @field<waarvoor> gebeurde omdat @field<waarom>. Maar dat is natuurlijk geen excuus. Ik had eigenlijk @field<anders> . </p> <p> Het spijt me. Ik hoop dat je mijn excuses wilt aanvaarden en dat we dit achter ons kunnen laten. </p> @sqlend <p></p> <p></p> <p></p> <p></p> <p></p> <p></p> <p></p> <H1>Clues</H1> <table> <tr><td><i>naam</i></td><td><i>waarde</i></td></tr> @sqlselect person, name, value from clues where person = @param<pid> order by id; <tr><td>@field<name></td><td>@field<value></td></tr> @sqlend </table> <H1>Gesprek</H1> @sqlwith rep as ( select id, to_char(t.pit, 'HH24:MI:SS' ) as tijdstip, 'prsn: ' as speaker, rtrim((t.intent->>'text'),E'\n') as tekst, 1 as rank from trail t where person = @param<pid> UNION select id, to_char(t.pit, 'HH24:MI:SS' ) as tijdstip, 'bot : ' as speaker, t.output as tekst, 2 as rank from trail t where person = @param<pid> order by id, tijdstip, rank ) select tijdstip, speaker, tekst from rep; <p><b>@field<tijdstip></b> <i>@field<speaker></i>@field<tekst> </p> @sqlend <H1>Intents en gematchte Clues</H1> <table> <tr><td><i>tijdstip</i></td><td>intent</td><td>confidence</td><td>clue: waarde</td></tr> @sqlselect to_char( pit, 'HH24:MI:SS') as tijdstip, ((intent->>'intent')::jsonb)->>'name' as name, to_char( (((intent->>'intent')::jsonb)->>'confidence')::float, '0.99' ) as conf, ((intent->>'entities')::jsonb)->0->>'entity'||': '||(((intent->>'entities')::jsonb)->0->>'value') as slot from trail where person = @param<pid> order by pit; <tr><td>@field<tijdstip></td><td>@field<name></td><td>@field<conf></td><td>@field<slot></td></tr> @sqlend </table> </body> </html>
Het gesprek met 582 leverde de volgende intents op:
| id | tijdstip | name | conf | slot |
|---|---|---|---|---|
| 2057 | 20:32:50 | |||
| 2058 | 20:33:03 | noemtresultaat2 | 0.17 | verkeersissues: lastig |
| 2059 | 20:33:14 | leeftijd | 0.16 | |
| 2060 | 20:33:32 | noemtresultaat2 | 0.25 | |
| 2061 | 20:33:52 | noemtresultaat2 | 0.17 | |
| 2062 | 20:34:05 | noemtresultaat2 | 0.20 | |
| 2063 | 20:34:13 | noemtresultaat2 | 0.21 | |
| 2064 | 20:34:24 | noemtresultaat2 | 0.19 | |
| 2065 | 20:34:34 | noemtresultaat2 | 0.22 | |
| 2066 | 20:34:49 | noemtresultaat2 | 0.19 | |
| 2067 | 20:35:04 | naam | 0.44 | |
| 2068 | 20:35:10 | leeftijd | 0.30 | leeftijd: 24 |
| 2069 | 20:35:17 | leeftijd | 0.30 | leeftijd: 24 |
| 2070 | 20:35:38 | noemtresultaat2 | 0.22 | |
| 2071 | 20:35:38 | noemtresultaat2 | 0.22 | |
| 2072 | 20:36:02 | herhalen | 0.28 | |
| 2073 | 20:36:19 | leeftijd | 0.37 | leeftijd: 582 |
| 2074 | 20:36:36 | noemtresultaat2 | 0.31 | |
| 2075 | 20:36:36 | noemtresultaat2 | 0.31 | |
| 2076 | 20:36:51 | noemtresultaat2 | 0.18 | |
| 2077 | 20:36:51 | noemtresultaat2 | 0.18 |
Het gesprek met persoon 582 is als volgt verlopen:
| tijdstip | speaker | tekst |
|---|---|---|
| 20:32:50 | prsn: | |
| 20:32:50 | bot : | Hoi, wat fijn dat je er bent en welkom op ons hoofdkantoor. ik hoop dat je het een beetje hebt kunnen vinden? |
| 20:33:03 | prsn: | Ja dat is wel lastig |
| 20:33:03 | bot : | En, ben je hier tevreden over? |
| 20:33:14 | prsn: | Nou ja ik ben er dus ik vind ik ben fijn fijn dat ik er ben |
| 20:33:14 | bot : | Ok, dat is goed om te weten, ik kon het niet terugvinden op je CV. Mijn naam is harald, human resources, met mij zul je te maken krijgen mocht je hier in dienst komen, en ik ben ook het eerste aanspreekpunt binnen het sollicitatietraject. Ben je klaar voor de eerste vraag? |
| 20:33:32 | prsn: | Ja hoor kom maar op |
| 20:33:32 | bot : | OK, vertel eens over een situatie waarin er een hoge werkdruk was en je achter liep op schema? |
| 20:33:52 | prsn: | nou we moesten personeelstekort we moesten veel mensen aannemen en dat was heel heel ingewikkeld |
| 20:33:52 | bot : | Waarom heb je ervoor gekozen het op die manier aan te pakken? |
| 20:34:05 | prsn: | Nou ja de aanpak was best goed en we hebben dat |
| 20:34:05 | bot : | Waarom heb je voor deze aanpak gekozen? |
| 20:34:13 | prsn: | omdat hij me het meest effectief Leek |
| 20:34:13 | bot : | Wat was het resultaat? |
| 20:34:24 | prsn: | Ja dus dat was dat we toch 90% hebben gehaald van wat we moesten nemen erg goed |
| 20:34:24 | bot : | ja hoor, Wat was het resultaat? |
| 20:34:34 | prsn: | Ja dat zeg ik We hebben het gehaald 90% net niet |
| 20:34:34 | bot : | Wat was het resultaat? |
| 20:34:49 | prsn: | Het resultaat was dat ze het gehaald hebben |
| 20:34:49 | bot : | Nou, gelukkig dat je er toch bent gekomen. Je komt hier solliciteren op positie inbound recruiter, allereerst wil ik je wat praktische vragen stellen. daarna volgen wat uitgebreidere vragen. Hoe spreek je je voornaam uit? |
| 20:35:04 | prsn: | Karel |
| 20:35:04 | bot : | Ok, Karel. En wat is je leeftijd? |
| 20:35:10 | prsn: | 24 |
| 20:35:10 | bot : | OK, Ok, Karel. En wat is je leeftijd? |
| 20:35:17 | prsn: | 24 |
| 20:35:17 | bot : | hm, en verder |
| 20:35:38 | prsn: | hun en verder herhaal het eens |
| 20:35:38 | bot : | Ok, Karel, dat waren mijn vragen. Hartelijk dank voor je tijd. Als je de hoorn zo ophangt zie je meteen de uitkomsten van deze assessment. En je weet meteen of we je uitnodigen voor een volgende ronde. Plak de resultaten op. |
| 20:35:38 | prsn: | hun en verder herhaal het eens |
| 20:35:38 | bot : | Hoe heb je dat toen aangepakt? |
| 20:36:02 | prsn: | niet |
| 20:36:02 | bot : | hm, en verder |
| 20:36:19 | prsn: | 582 |
| 20:36:19 | bot : | hm, en verder |
| 20:36:36 | prsn: | vroem |
| 20:36:36 | bot : | hm, en verder |
| 20:36:36 | prsn: | vroem |
| 20:36:36 | bot : | |
| 20:36:51 | prsn: | nou |
| 20:36:51 | bot : | hm, en verder |
| 20:36:51 | prsn: | nou |
| 20:36:51 | bot : |
Met als gevonden clues:
| person | name | value |
|---|---|---|
| 582 | afdeling | |
| 582 | drinken | |
| 582 | drinken | |
| 582 | functie | |
| 582 | geslacht | m |
| 582 | lastinput | |
| 582 | lastoutput | |
| 582 | leeftijd | 24 |
| 582 | naam | Karel |
| 582 | positiekandidaat | |
| 582 | positiekandidaat | |
| 582 | resultaat1 | Het resultaat was dat ze het gehaald hebben |
| 582 | resultaat1 | |
| 582 | resultaat2 | Ja dus dat was dat we toch 90% hebben gehaald van wat we moesten nemen erg goed |
| 582 | resultaat2 | |
| 582 | situatie1 | nou we moesten personeelstekort we moesten veel mensen aannemen en dat was heel heel ingewikkeld |
| 582 | stappen2 | |
| 582 | stappen2 | |
| 582 | taak1 | niet |
| 582 | taak1 | |
| 582 | taak1waarom | Nou ja de aanpak was best goed en we hebben dat |
| 582 | taak1waarom | |
| 582 | tevreden2 | Nou ja ik ben er dus ik vind ik ben fijn fijn dat ik er ben |
| 582 | tevreden2 | |
| 582 | vacature | |
| 582 | verkeersissues | lastig |
| 582 | waaromstappen | omdat hij me het meest effectief Leek |
| 582 | waaromstappen | |
| 582 | werkgever | |
| 582 | wilgesprek | Ja hoor kom maar op |
4 Sorry
Een van de instanties van Pinteresque is Sorry, een kunstwerk van Collectief Smelt (Rotterdam) in het kader van Tech Sorry van Setup.
De bot is licht aangepast en het model is uitgebreid en specifiek voor Sorry.
In het kunstwerk speelt de bot de rol van uitlegger/interviewer. De bezoeker wordt geintroduceerd en er worden vragen gesteld. Na de tekst ‘ontvang excuses van ons samen’ komt een spreker tevoorschijn die het gepubliceerde excuus (https://htip.helberg.nl/pin/excuses/nieuwste.html) voorleest. Nadat het voorlezen klaar is, start de spreker de afscheids-audio.
De Raspberry Pi zit in een casing met een afstandsbediening erbij.
De afstandsbediening heeft vier functies:
- uit
- zet de computer uit. 20 seconden na uit-zetten mag de stroom er af. Aanzetten kan niet met de afstandsbediening. De computer start automatisch na aansluiten op het stroomnet.
- bot
- herstart de bot. Dit is eigenlijk niet nodig, maar mocht er iets onverklaarbaars misgaan, dan is dit de manier om de bot-software helemaal opnieuw te starten.
- start sessie
- bij elke aanvang van een sessie kan die gestart worden met deze knop. Als een bezoeker bereid is om mee te doen en binnen luisterbereik is van de audio-installatie, dan kan de knop ingedrukt worden.
- bye
- na het uitspreken van het excuus wordt de afscheids-audio afgespeeld. Met deze knop begint die. Na het volledig afspelen van de afscheids-audio kan er weer gestart worden.
De computer heeft internet nodig voor het vertalen van audio naar
tekst. De audio gaat, per uitgesproken zin, naar Google toe; die
maakt er tekst van. Daarna gaat de tekst naar een dienst voor
grammaticale analyse (geleverd door iVinci). De computer gebruikt
voor internet-toegang Wifi. Voorgeconfigureerd zijn:
SETUP: setuputrecht en BibliotheekUtrecht: @BU@WORK. Nieuwe
toegang moet op de SD-card worden toegevoegd in
/etc/wpa_supplicant/wpa_supplicant.conf.
5 Colofon
Joost Helberg werkt voor Cistus; Cistus maakt onderdeel uit van een samenwerkingsverband op het terrein van zelflerende software: iVinci.
Dit document is geschreven met de applicatie org-mode, onderdeel van GNU Emacs. Het Charter lettertype wordt gebruikt voor de pdf-export, die met behulp van LaTeX tot stand komt. Voor de exports naar html wordt een stylesheet gebruikt met het lettertype Droid Serif. Voor tekst en markdown worden geen aanwijzingen als stylesheets of lettertypes opgenomen. De tekst-encoding is UTF-8.
Voetnoten:
dat hier ook nog een praktische noodzakelijkheid aan ten grondslag ligt komt later; het heeft te maken met het probleem dat ASR niet weet wie er spreekt, een mens of de TTS van de bot
je zou op z'n IT's kunnen spreken van formele parameters (naam) en actuele parameters (Piet of Karel) bij zo'n slot-voorbeeld.
dat kan opgelost worden door er tijd bij op te tellen afhankelijk van de lengte van de tekst. De bot merkt nl. niet op dat de TTS nog praat, de bot is direct klaar met uitspreken. De reset-silence-breaker kan natuurlijk na de laatste output, maar dat is niet goed genoeg. de lengte van de tekst speelt ook een rol.
natuurlijk kunnen we Pinteresque zo maken dat ie de Nederlandse taal wel begrijpt en dat bedoelingen genoeg zijn om aan een zin-generator te geven die er vervolgens goed Nederlands van maakt. Dat valt echter om twee redenen buiten de scope van dit project: 1. daar gaan maanden onderzoek in zitten en 2. het sterke vermoeden is dat de huidige opzet gesprekken oplevert die voldoende natuurgetrouw zijn. Het staat volgende ontwikkelaars vrij om tussen Pinteresque en TTS een zins-generatie-module te zetten. De toepassing, een oppervlakkig gesprek tussen kapper en klant, zal voldoende gediend worden met deze beperking.
dat valt een beetje tegen, Frog gebruikt 3GB!
matchen van positief/negatief komt later
for-loops zijn een bron van bugs, vermijden daarvan is een vorm van defensief coderen.
los dit op, b.v. person in
(select id from persons where isrobot and
(starttime > CURRENT_TIME - interval '1 day' or
id > max(id) - 10) ) oid.
is dat zo?
voor het later wel hergebruiken van personen, b.v. als personas, is het model wel van belang en moet het wel ingevuld worden.
doe wat aan synchroniseren van echo op /dev/<pid>/fd/0.
in een eerste versie van Pinteresque gebruikt de Orchestrator de API naar Frog zelf.
ik kan zo snel niet bedenken waarom de
-i zinnig zou zijn